并发编程
并发编程简介
java是一个支持多线程的开发语言。多线程可以在包含多个CPU核心的机器上同时处理多个不同的 任务,优化资源的使用率,提升程序的效率。在一些对性能要求比较高场合,多线程是java程序调优的 重要方面。 大厂面试中比较重要的内容除了算法,就是并发编程。并发编程是最能体现一个程序员功底的方面之一。 并发编程也是在面试中很能加分的部分。 Java并发编程主要涉及以下几个部分:
1. 并发编程三要素
- 原子性:即一个不可再被分割的颗粒。在Java中原子性指的是一个或多个操作要么全部执行成 功要么全部执行失败。
- 有序性:程序执行的顺序按照代码的先后顺序执行。(处理器可能会对指令进行重排序)
- 可见性:当多个线程访问同一个变量时,如果其中一个线程对其作了修改,其他线程能立即获 取到最新的值。
2.线程的五大状态 创建状态:当用 new 操作符创建一个线程的时候 就绪状态:调用 start 方法,处于就绪状态的线程并不一定马上就会执行 run 方法,还需要等待CPU的调度 运行状态:CPU 开始调度线程,并开始执行 run 方法 阻塞状态:线程的执行过程中由于一些原因进入阻塞状态比如:调用 sleep 方法、尝试去得到一个锁等等 死亡状态:run 方法执行完 或者 执行过程中遇到了一个异常
3.悲观锁与乐观锁 悲观锁:每次操作都会加锁,会造成线程阻塞。 乐观锁:每次操作不加锁而是假设没有冲突而去完成某项操作,如果因为冲突失败就重试,直 到成功为止,不会造成线程阻塞。
4.线程之间的协作 线程间的协作有:wait/notify/notifyAll等
5.synchronized 关键字 synchronized是Java中的关键字,是一种同步锁。它修饰的对象有以下几种: 修饰一个代码块:被修饰的代码块称为同步语句块,其作用的范围是大括号{}括起来 的代码,作用的对象是调用这个代码块的对象 修饰一个方法:被修饰的方法称为同步方法,其作用的范围是整个方法,作用的对象 是调用这个方法的对象 修饰一个静态的方法:其作用的范围是整个静态方法,作用的对象是这个类的所有对 象 修饰一个类:其作用的范围是synchronized后面括号括起来的部分,作用主的对象 是这个类的所有对象。
6.CAS CAS全称是Compare And Swap,即比较替换,是实现并发应用到的一种技术。操作包含三个操作数—内存位置(V)、预期原值(A)和新值(B)。 如果内存位置的值与预期原值相匹配, 那么处理器会自动将该位置值更新为新值 。否则,处理器不做任何操作。 CAS存在三大问题:ABA问题,循环时间长开销大,以及只能保证一个共享变量的原子操作。
7.线程池 如果我们使用线程的时候就去创建一个线程,虽然简单,但是存在很大的问题。如果并发的线 程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大 大降低系统的效率,因为频繁创建线程和销毁线程需要时间。线程池通过复用可以大大减少线 程频繁创建与销毁带来的性能上的损耗。
常见的多线程面试题有: 1.重排序有哪些分类?如何避免? 2.Java 中新的Lock接口相对于同步代码块(synchronized block)有什么优势?如果让你实现一个高性能缓存,支持并发读取和单一写入,你如何保证数据完整性。 3.如何在Java中实现一个阻塞队列。 4.写一段死锁代码。说说你在Java中如何解决死锁。 5.volatile变量和atomic变量有什么不同? 6.为什么要用线程池? 7.实现Runnable接口和Callable接口的区别 8.执行execute()方法和submit()方法的区别是什么呢? 9.AQS的实现原理是什么? 10.java API中哪些类中使用了AQS? 11....
并发编程课程很多内容会从JDK源码解析相关原理
主要内容包括:
1.多线程&并发设计原理 并发核心概念 并发的问题 JMM内存模型
2.JUC 并发容器 同步工具类 Atomic类 Lock与Condition
3.线程池与Future 线程池的实现原理 线程池的类继承体系 ThreadPoolExecutor Executors工具类 ScheduledThreadPool Executor CompletableFuture用法
4.ForkJoinPool ForkJoinPool用法 核心数据结构 工作窃取队列 ForkJoinPool状态控制 Worker线程的阻塞-唤醒机制 任务的提交过程分析 工作窃取算法 任务的执行过程分析 ForkJoinTask 的 fork/join ForkJoinPool的优雅关闭
5.多线程设计模式 Single Threaded Execution模式 Immutable模式 Guarded Suspension模式 Balking模式 Producer-Consumer模式 Read-Write Lock模式 Thread-Per-Message模式 Worker Thread模式 Future模式
第一部分:多线程&并发设计原理
1. 多线程回顾
1.1 Thread和Runnable
1.1.1 Java中的线程
创建执行线程有两种方法:
- 扩展Thread 类。 实现Runnable 接口。
扩展Thread类的方式创建新线程:
package com.lagou.concurrent.demo;
public class MyThread extends Thread {
@Override public void run() {
while (true) {
System.out.println(Thread.currentThread().getName() + " 运行了");
try {
Thread.sleep(800);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package com.lagou.concurrent.demo;
public class Main {
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
}
}
实现Runnable接口的方式创建线程:
package com.lagou.concurrent.demo;
public class MyRunnable implements Runnable {
@Override
public void run() {
while (true) {
System.out.println(Thread.currentThread().getName() + " 运行了");
try {
Thread.sleep(800);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
package com.lagou.concurrent.demo;
public class Main {
public static void main(String[] args) {
Thread thread = new Thread(new MyRunnable());
thread.start();
}
}
1.1.2 Java中的线程:特征和状态
1.所有的Java 程序,不论并发与否,都有一个名为主线程的Thread 对象。执行该程序时, Java 虚拟机( JVM )将创建一个新Thread 并在该线程中执行main()方法。这是非并发应用程序中唯一的线程,也是并发应用程序中的第一个线程。
2.Java中的线程共享应用程序中的所有资源,包括内存和打开的文件,快速而简单地共享信息。 但是必须使用同步避免数据竞争。
3.Java中的所有线程都有一个优先级,这个整数值介于Thread.MIN_PRIORITY(1)和 Thread.MAX_PRIORITY(10)之间,默认优先级是Thread.NORM_PRIORITY(5)。线程的 执行顺序并没有保证,通常,较高优先级的线程将在较低优先级的钱程之前执行。
4.在Java 中,可以创建两种线程:
- 守护线程。
- 非守护线程。
区别在于它们如何影响程序的结束。 Java程序结束执行过程的情形:
- 程序执行Runtime类的exit()方法, 而且用户有权执行该方法。
- 应用程序的所有非守护线程均已结束执行,无论是否有正在运行的守护线程。
守护线程通常用在作为垃圾收集器或缓存管理器的应用程序中,执行辅助任务。在线程start之前调用isDaemon()方法检查线程是否为守护线程,也可以使用setDaemon()方法将某个线程确立为守护线程。
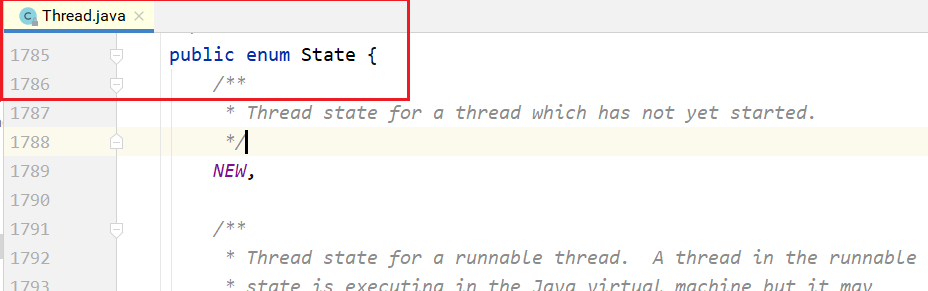
5.Thread.States类中定义线程的状态如下:
- NEW:Thread对象已经创建,但是还没有开始执行。
- RUNNABLE:Thread对象正在Java虚拟机中运行。
- BLOCKED : Thread对象正在等待锁定。
- WAITING:Thread 对象正在等待另一个线程的动作。
- TIME_WAITING:Thread对象正在等待另一个线程的操作,但是有时间限制。
- TERMINATED:Thread对象已经完成了执行。
getState()方法获取Thread对象的状态,可以直接更改线程的状态。 在给定时间内,线程只能处于一个状态。这些状态是JVM使用的状态,不能映射到操作系统的线程状态。 线程状态的源码:
1.1.3 Thread类和Runnable 接口
Runnable接口只定义了一种方法:run()方法。这是每个线程的主方法。当执行start()方法启动新线程时,它将调用run()方法。 Thread类其他常用方法: 获取和设置Thread对象信息的方法。
- getId():该方法返回Thread对象的标识符。该标识符是在钱程创建时分配的一个正 整 数 。 在 线 程 的 整 个 生 命 周 期 中 是 唯 一 且 无 法 改 变 的 。
- getName()/setName():这两种方法允许你获取或设置Thread对象的名称。这个名 称是一个String对象,也可以在Thread类的构造函数中建立。
- getPriority()/setPriority():你可以使用这两种方法来获取或设置Thread对象的优先 级。
- isDaemon()/setDaemon():这两种方法允许你获取或建立Thread对象的守护条件。
- getState():该方法返回Thread对象的状态。
interrupt():中断目标线程,给目标线程发送一个中断信号,线程被打上中断标记。
interrupted():判断目标线程是否被中断,但是将清除线程的中断标记。
isinterrupted():判断目标线程是否被中断,不会清除中断标记。
sleep(long ms):该方法将线程的执行暂停ms时间。
join():暂停线程的执行,直到调用该方法的线程执行结束为止。可以使用该方法等待另一个Thread对象结束。
setUncaughtExceptionHandler():当线程执行出现未校验异常时,该方法用于建立未校验异常的控制器。
currentThread():Thread类的静态方法,返回实际执行该代码的Thread对象。
join示例程序:
public class MyThread extends Thread {
@Override
public void run() {
for (int i = 0; i < 10; i++) {
System.out.println("MyThread线程:" + i);
}
}
}
public class Main {
public static void main(String[] args) throws InterruptedException {
MyThread myThread = new MyThread();
myThread.start();
myThread.join();
System.out.println("main线程 - 执行完成");
}
}
1.1.4 Callable
Callable 接口是一个与Runnable 接口非常相似的接口。Callable 接口的主要特征如下。
- 接口。有简单类型参数,与call()方法的返回类型相对应。
- 声明了call()方法。执行器运行任务时,该方法会被执行器执行。它必须返回声明中指定类型的 对象。
- call()方法可以抛出任何一种校验异常。可以实现自己的执行器并重载afterExecute()方法来处 理这些异常。
package com.lagou.concurrent.demo;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.FutureTask;
public class Main {
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable myCallable = new MyCallable();
// 设置Callable对象,泛型表示Callable的返回类型
FutureTask<String> futureTask = new FutureTask<String>(myCallable);
// 启动处理线程
new Thread(futureTask).start();
// 同步等待线程运行的结果
String result = futureTask.get();
// 5s后得到结果
System.out.println(result);
}
}
package com.lagou.concurrent.demo;
import java.util.concurrent.Callable;
public class MyCallable implements Callable<String> {
@Override
public String call() throws Exception {
Thread.sleep(5000);
return "hello world call() invoked!";
}
}
package com.lagou.concurrent.demo;
import java.util.concurrent.*;
public class Main2 {
public static void main(String[] args) throws ExecutionException, InterruptedException {
ThreadPoolExecutor executor = new ThreadPoolExecutor(5, 5, 1, TimeUnit.SECONDS, new ArrayBlockingQueue<>(10)) {
@Override
protected void afterExecute(Runnable r, Throwable t) {
super.afterExecute(r, t);
}
};
Future<String> future = executor.submit(new MyCallable());
String s = future.get();
System.out.println(s);
executor.shutdown();
}
}
1.2 synchronized关键字
1.2.1锁的对象
synchronized关键字“给某个对象加锁”,示例代码:
public Class MyClass {
public void synchronized method1() {
// ...
}
public static void synchronized method2() {
// ...
}
}
等价于:
public class MyClass {
public void method1() {
synchronized(this) {
// ...
}
}
public static void method2() {
synchronized(MyClass.class) {
// ...
}
}
}
实例方法的锁加在对象myClass上;静态方法的锁加在MyClass.class上。
1.2.2锁的本质
如果一份资源需要多个线程同时访问,需要给该资源加锁。加锁之后,可以保证同一时间只能有一个线程访问该资源。资源可以是一个变量、一个对象或一个文件等。
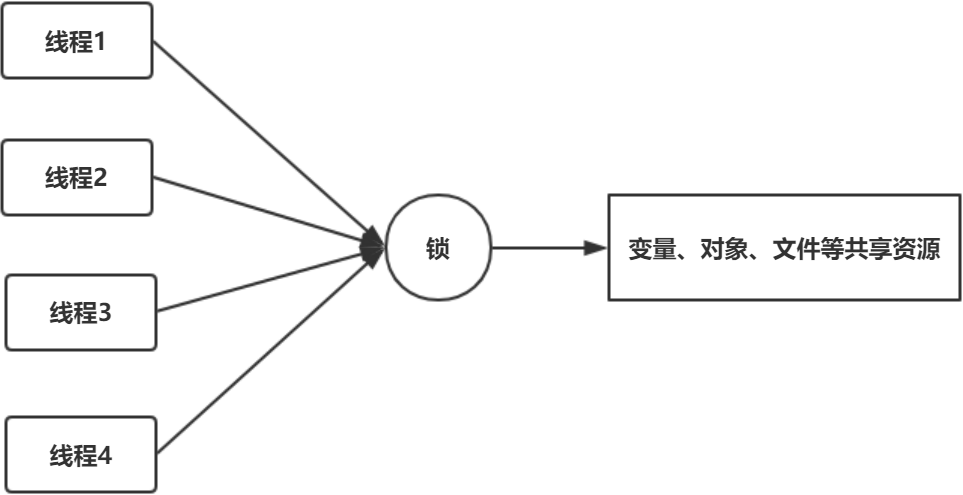
锁是一个“对象”,作用如下:
这个对象内部得有一个标志位(state变量),记录自己有没有被某个线程占用。最简单的情况是这个state有0、1两个取值,0表示没有线程占用这个锁,1表示有某个线程占用了这个锁。
如果这个对象被某个线程占用,记录这个线程的thread ID。
这个对象维护一个thread id list,记录其他所有阻塞的、等待获取拿这个锁的线程。在当前线程释放锁之后从这个thread id list里面取一个线程唤醒。
要访问的共享资源本身也是一个对象,例如前面的对象myClass,这两个对象可以合成一个对象。代码就变成synchronized(this) {…},要访问的共享资源是对象a,锁加在对象a上。当然,也可以另外新建一个对象,代码变成synchronized(obj1) {…}。这个时候,访问的共享资源是对象a,而锁加在新建的对象obj1上。
资源和锁合二为一,使得在Java里面,synchronized关键字可以加在任何对象的成员上面。这意味着,这个对象既是共享资源,同时也具备“锁”的功能!
1.2.3实现原理
锁如何实现? 在对象头里,有一块数据叫Mark Word。在64位机器上,Mark Word是8字节(64位)的,这64位中有2个重要字段:锁标志位和占用该锁的thread ID。因为不同版本的JVM实现,对象头的数据结构会有各种差异。
1.3 wait与notify
1.3.1 生产者−消费者模型
生产者-消费者模型是一个常见的多线程编程模型,如下图所示:
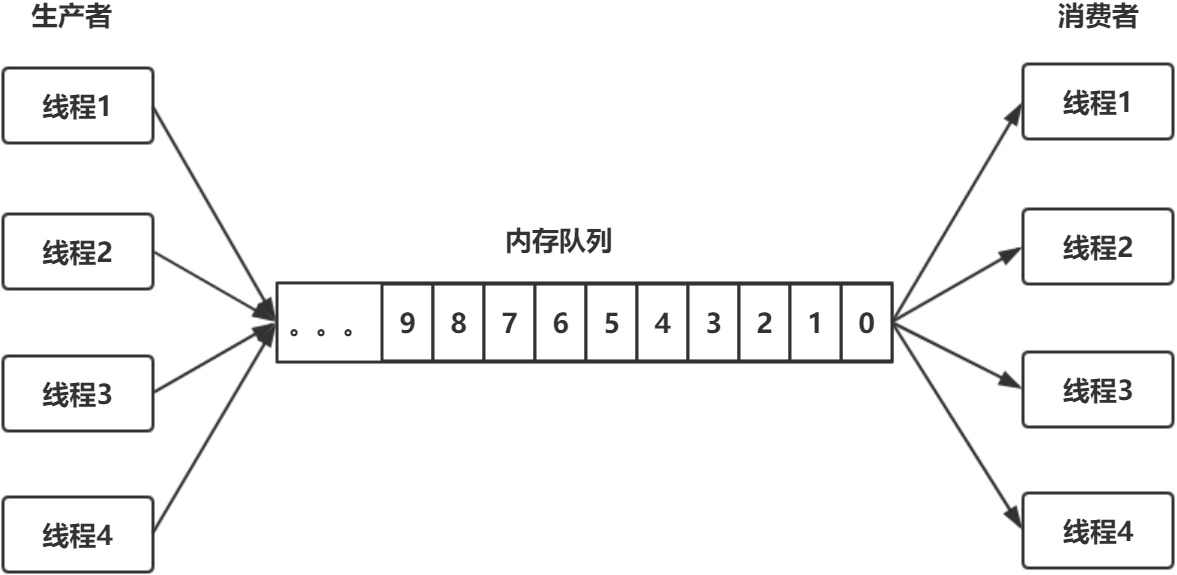
一个内存队列,多个生产者线程往内存队列中放数据;多个消费者线程从内存队列中取数据。要实 现这样一个编程模型,需要做下面几件事情: 1.内存队列本身要加锁,才能实现线程安全。 2.阻塞。当内存队列满了,生产者放不进去时,会被阻塞;当内存队列是空的时候,消费者无事 可做,会被阻塞。 3.双向通知。消费者被阻塞之后,生产者放入新数据,要notify()消费者;反之,生产者被阻塞之 后,消费者消费了数据,要notify()生产者。
第1件事情必须要做,第2件和第3件事情不一定要做。例如,可以采取一个简单的办法,生产者放 不进去之后,睡眠几百毫秒再重试,消费者取不到数据之后,睡眠几百毫秒再重试。但这个办法效率低 下,也不实时。所以,我们只讨论如何阻塞、如何通知的问题。
1.如何阻塞? 办法1:线程自己阻塞自己,也就是生产者、消费者线程各自调用wait()和notify()。 办法2:用一个阻塞队列,当取不到或者放不进去数据的时候,入队/出队函数本身就是阻塞的。
2.如何双向通知? 办法1:wait()与notify()机制。
办法2:Condition机制。
单个生产者单个消费者线程的情形:
package com.lagou.concurrent.demo; public class Main {
public static void main(String[] args) {
MyQueue myQueue = new MyQueue();
ProducerThread producerThread = new ProducerThread(myQueue);
ConsumerThread consumerThread = new ConsumerThread(myQueue);
producerThread.start();
consumerThread.start();
}
}
package com.lagou.concurrent.demo; public class MyQueue { private String[] data = new String[10]; private int getIndex = 0; private int putIndex = 0; private int size = 0; public synchronized void put(String element) { if (size == data.length) { try {wait(); } catch (InterruptedException e) { e.printStackTrace(); } }data[putIndex] = element; ++putIndex; if (putIndex == data.length) putIndex = 0; ++size; notify(); }public synchronized String get() { if (size == 0) { try {wait(); } catch (InterruptedException e) { e.printStackTrace(); } }String result = data[getIndex]; ++getIndex; if (getIndex == data.length) getIndex = 0; --size; notify(); return result; } }
package com.lagou.concurrent.demo;
import java.util.Random; public class ProducerThread extends Thread { private final MyQueue myQueue; private final Random random = new Random(); private int index = 0; public ProducerThread(MyQueue myQueue) { this.myQueue = myQueue; }@Override public void run() { while (true) { String tmp = "ele-" + index; myQueue.put(tmp); System.out.println("添加元素:" + tmp); index++; try {Thread.sleep(random.nextInt(1000)); } catch (InterruptedException e) { e.printStackTrace(); } } } }
package com.lagou.concurrent.demo; import java.util.Random; public class ConsumerThread extends Thread { private final MyQueue myQueue; private final Random random = new Random(); public ConsumerThread(MyQueue myQueue) { this.myQueue = myQueue; }@Override public void run() { while (true) { String s = myQueue.get(); System.out.println("\t\t消费元素:" + s); try {Thread.sleep(random.nextInt(1000)); } catch (InterruptedException e) { e.printStackTrace(); } } } }
多个生产者多个消费者的情形:
package com.lagou.concurrent.demo; public class Main2 { public static void main(String[] args) { MyQueue2 myQueue = new MyQueue2(); for (int i = 0; i < 3; i++) { new ConsumerThread(myQueue).start(); }for (int i = 0; i < 5; i++) { new ProducerThread(myQueue).start(); } } }
package com.lagou.concurrent.demo; public class MyQueue2 extends MyQueue { private String[] data = new String[10]; private int getIndex = 0; private int putIndex = 0; private int size = 0; @Override public synchronized void put(String element) { if (size == data.length) { try {wait(); } catch (InterruptedException e) { e.printStackTrace(); }put(element); } else { put0(element); notify(); } }private void put0(String element) { data[putIndex] = element; ++putIndex; if (putIndex == data.length) putIndex = 0; ++size; }@Override public synchronized String get() { if (size == 0) { try {wait(); } catch (InterruptedException e) {
e.printStackTrace(); }return get(); } else { String result = get0(); notify(); return result; } }private String get0() { String result = data[getIndex]; ++getIndex; if (getIndex == data.length) getIndex = 0; --size; return result; } }
1.3.2为什么必须和synchronized一起使用
在Java里面,wait()和notify()是Object的成员函数,是基础中的基础。为什么Java要把wait()和 notify()放在如此基础的类里面,而不是作为像Thread一类的成员函数,或者其他类的成员函数呢? 先看为什么wait()和notify()必须和synchronized一起使用?请看下面的代码:
class MyClass1 { private Object obj1 = new Object(); public void method1() { synchronized(obj1) { //... obj1.wait(); //... } }public void method2() { synchronized(obj1) { //... obj1.notify(); //... } } }
或者下面的代码:
public class MyClass1 { public void synchronized method1() { //... this.wait(); //... }public void synchronized method2() { //... this.notify(); //... } }
然后,开两个线程,线程A调用method1(),线程B调用method2()。答案已经很明显:两个线程之 间要通信,对于同一个对象来说,一个线程调用该对象的wait(),另一个线程调用该对象的notify(),该 对象本身就需要同步!所以,在调用wait()、notify()之前,要先通过synchronized关键字同步给对象, 也就是给该对象加锁。
synchronized关键字可以加在任何对象的实例方法上面,任何对象都可能成为锁。因此,wait()和notify()只能放在Object里面了。
1.3.3为什么wait()的时候必须释放锁
当线程A进入synchronized(obj1)中之后,也就是对obj1上了锁。此时,调用wait()进入阻塞状态, 一直不能退出synchronized代码块;那么,线程B永远无法进入synchronized(obj1)同步块里,永远没 有机会调用notify(),发生死锁。 这就涉及一个关键的问题:在wait()的内部,会先释放锁obj1,然后进入阻塞状态,之后,它被另外 一个线程用notify()唤醒,重新获取锁!其次,wait()调用完成后,执行后面的业务逻辑代码,然后退出synchronized同步块,再次释放锁。 wait()内部的伪代码如下:
wait() {
// 释放锁
// 阻塞,等待被其他线程notify
// 重新获取锁
}
如此则可以避免死锁。
1.3.4wait()与notify()的问题
以上述的生产者-消费者模型来看,其伪代码大致如下:
public void enqueue() { synchronized(queue) { while (queue.full()) { queue.wait();
}//... 数据入列 queue.notify(); // 通知消费者,队列中有数据了。 } }public void dequeue() { synchronized(queue) { while (queue.empty()) { queue.wait(); }// 数据出队列 queue.notify(); // 通知生产者,队列中有空间了,可以继续放数据了。 } }
生产者在通知消费者的同时,也通知了其他的生产者;消费者在通知生产者的同时,也通知了其他 消费者。原因在于wait()和notify()所作用的对象和synchronized所作用的对象是同一个,只能有一个对 象,无法区分队列空和列队满两个条件。这正是Condition要解决的问题。
1.4 InterruptedException与interrupt()方法
1.4.1Interrupted异常
什么情况下会抛出Interrupted异常 假设while循环中没有调用任何的阻塞函数,就是通常的算术运算,或者打印一行日志,如下所示。
package com.lagou.concurrent.demo; public class MyThread extends Thread { @Override public void run() { while (true) { boolean interrupted = isInterrupted(); System.out.println("中断标记:" + interrupted); } } }
这个时候,在主线程中调用一句thread.interrupt(),请问该线程是否会抛出异常?不会。
package com.lagou.concurrent.demo; public class Main42 { public static void main(String[] args) throws InterruptedException { MyThread42 myThread = new MyThread42(); myThread.start(); Thread.sleep(10); myThread.interrupt(); Thread.sleep(100); System.exit(0); } }
只有那些声明了会抛出InterruptedException的函数才会抛出异常,也就是下面这些常用的函数:
public static native void sleep(long millis) throws InterruptedException {...} public final void wait() throws InterruptedException {...} public final void join() throws InterruptedException {...}
1.4.2轻量级阻塞与重量级阻塞
能够被中断的阻塞称为轻量级阻塞,对应的线程状态是WAITING或者TIMED_WAITING;而像synchronized 这种不能被中断的阻塞称为重量级阻塞,对应的状态是 BLOCKED。如图所示:调用不同的方法后,一个线程的状态迁移过程。

初始线程处于NEW状态,调用start()开始执行后,进入RUNNING或者READY状态。如果没有调用 任何的阻塞函数,线程只会在RUNNING和READY之间切换,也就是系统的时间片调度。这两种状态的 切换是操作系统完成的,除非手动调用yield()函数,放弃对CPU的占用。 一旦调用了图中的任何阻塞函数,线程就会进入WAITING或者TIMED_WAITING状态,两者的区别 只是前者为无限期阻塞,后者则传入了一个时间参数,阻塞一个有限的时间。如果使用了synchronized 关键字或者synchronized块,则会进入BLOCKED状态。
不太常见的阻塞/唤醒函数,LockSupport.park()/unpark()。这对函数非常关键,Concurrent包中 Lock的实现即依赖这一对操作原语。 因此thread.interrupted()的精确含义是“唤醒轻量级阻塞”,而不是字面意思“中断一个线程”。
thread.isInterrupted()与Thread.interrupted()的区别 因为 thread.interrupted()相当于给线程发送了一个唤醒的信号,所以如果线程此时恰好处于WAITING或者TIMED_WAITING状态,就会抛出一个InterruptedException,并且线程被唤醒。而如果 线程此时并没有被阻塞,则线程什么都不会做。但在后续,线程可以判断自己是否收到过其他线程发来 的中断信号,然后做一些对应的处理。 这两个方法都是线程用来判断自己是否收到过中断信号的,前者是实例方法,后者是静态方法。二 者的区别在于,前者只是读取中断状态,不修改状态;后者不仅读取中断状态,还会重置中断标志位。
package com.lagou.concurrent.demo; public class Main { public static void main(String[] args) throws InterruptedException { MyThread myThread = new MyThread(); myThread.start(); Thread.sleep(10); myThread.interrupt(); Thread.sleep(7); System.out.println("main中断状态检查-1:" + myThread.isInterrupted()); System.out.println("main中断状态检查-2:" + myThread.isInterrupted()); } }
package com.lagou.concurrent.demo; public class MyThread extends Thread { @Override public void run() { int i = 0; while (true) { boolean interrupted = isInterrupted(); System.out.println("中断标记:" + interrupted); ++i; if (i > 200) { // 检查并重置中断标志。
boolean interrupted1 = Thread.interrupted(); System.out.println("重置中断状态:" + interrupted1); interrupted1 = Thread.interrupted(); System.out.println("重置中断状态:" + interrupted1); interrupted = isInterrupted(); System.out.println("中断标记:" + interrupted); break; }
} } }
1.5 线程的优雅关闭
1.5.1stop与destory函数
线程是“一段运行中的代码”,一个运行中的方法。运行到一半的线程能否强制杀死? 不能。在Java中,有stop()、destory()等方法,但这些方法官方明确不建议使用。原因很简单,如 果强制杀死线程,则线程中所使用的资源,例如文件描述符、网络连接等无法正常关闭。
因此,一个线程一旦运行起来,不要强行关闭,合理的做法是让其运行完(也就是方法执行完 毕),干净地释放掉所有资源,然后退出。如果是一个不断循环运行的线程,就需要用到线程间的通信 机制,让主线程通知其退出。
1.5.2守护线程
daemon线程和非daemon线程的对比:
package com.lagou.concurrent.demo; public class Main { public static void main(String[] args) { MyDaemonThread myDaemonThread = new MyDaemonThread(); // 设置为daemon线程
myDaemonThread.setDaemon(true); myDaemonThread.start(); // 启动非daemon线程,当非daemon线程结束,不管daemon线程是否结束,都结束JVM进 程。
new MyThread().start(); } }
package com.lagou.concurrent.demo; public class MyDaemonThread extends Thread { @Override public void run() { while (true) { System.out.println(Thread.currentThread().getName()); try {Thread.sleep(500);
} catch (InterruptedException e) { e.printStackTrace(); } } } }
package com.lagou.concurrent.demo; public class MyThread extends Thread { @Override public void run() { for (int i = 0; i < 10; i++) { System.out.println("非Daemon线程"); try {Thread.sleep(500); } catch (InterruptedException e) { e.printStackTrace(); } } } }
对于上面的程序,在thread.start()前面加一行代码thread.setDaemon(true)。当main(...)函数退出 后,线程thread就会退出,整个进程也会退出。 当在一个JVM进程里面开多个线程时,这些线程被分成两类:守护线程和非守护线程。默认都是非 守护线程。 在Java中有一个规定:当所有的非守护线程退出后,整个JVM进程就会退出。意思就是守护线程“不 算作数”,守护线程不影响整个 JVM 进程的退出。 例如,垃圾回收线程就是守护线程,它们在后台默默工作,当开发者的所有前台线程(非守护线 程)都退出之后,整个JVM进程就退出了。
1.5.3设置关闭的标志位
开发中一般通过设置标志位的方式,停止循环运行的线程。 代码1
package com.lagou.concurrent.demo; public class MyThread extends Thread{ private boolean running = true; @Override public void run() { while (running) { System.out.println("线程正在运行。。。"); try {
Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } }public void stopRunning() { this.running = false; }public static void main(String[] args) throws InterruptedException { MyThread myThread = new MyThread(); myThread.start(); Thread.sleep(5000); myThread.stopRunning(); myThread.join(); } }
但上面的代码有一个问题:如果MyThread t在while循环中阻塞在某个地方,例如里面调用了object.wait()函数,那它可能永远没有机会再执行 while( ! stopped)代码,也就一直无法退出循环。 此时,就要用到InterruptedException()与interrupt()函数。
2. 并发核心概念
2.1 并发与并行
在单个处理器上采用单核执行多个任务即为并发。在这种情况下,操作系统的任务调度程序会很快 从一个任务切换到另一个任务,因此看起来所有的任务都是同时运行的。 同一时间内在不同计算机、处理器或处理器核心上同时运行多个任务,就是所谓的“并行”。 另一个关于并发的定义是,在系统上同时运行多个任务(不同的任务)就是并发。而另一个关于并 行的定义是:同时在某个数据集的不同部分上运行同一任务的不同实例就是并行。 关于并行的最后一个定义是,系统中同时运行了多个任务。关于并发的最后一个定义是,一种解释 程序员将任务和它们对共享资源的访问同步的不同技术和机制的方法。 这两个概念非常相似,而且这种相似性随着多核处理器的发展也在不断增强。
2.2 同步
在并发中,我们可以将同步定义为一种协调两个或更多任务以获得预期结果的机制。同步的方式有 两种:
- 控制同步:例如,当一个任务的开始依赖于另一个任务的结束时,第二个任务不能再第一个任 务 完成之前开始。
- 数据访问同步:当两个或更多任务访问共享变量时,再任意时间里,只有一个任务可以访问该 变量。
与同步密切相关的一个概念时临界段。临界段是一段代码,由于它可以访问共享资源,因此再任何 给定时间内,只能被一个任务执行。互斥是用来保证这一要求的机制,而且可以采用不同的方式来实 现。
同步可以帮助你在完成并发任务的同时避免一些错误,但是它也为你的算法引入了一些开销。你必 须非常仔细地计算任务的数量,这些任务可以独立执行,而无需并行算法中的互通信。这就涉及并发算 法的粒度。如果算法有着粗粒度(低互通信的大型任务),同步方面的开销就会较低。然而,也许你不 会用到系统所有的核心。如果算法有者细粒度(高互通信的小型任务),同步方面的开销就会很高,而 且该算法的吞吐量可能不会很好。
并发系统中有不同的同步机制。从理论角度看,最流行的机制如下:
信号量(semaphore):一种用于控制对一个或多个单位资源进行访问的机制。它有一个用 于存放可用资源数量的变量,而且可以采用两种原子操作来管理该变量。互斥(mutex, mutual exclusion的简写形式)是一种特殊类型的信号量,它只能取两个值(即资源空闲和资源忙),而且只有将互斥设置为忙的那个进程才可以释放它。互斥可以通过保护临界段来帮助 你避免出现竞争条件。
监视器:一种在共享资源上实现互斥的机制。它有一个互斥、一个条件变量、两种操作(等待 条件和通报条件)。一旦你通报了该条件,在等待它的任务中只有一个会继续执行。
如果共享数据的所有用户都受到同步机制的保护,那么代码(或方法、对象)就是线程安全的。数 据的非阻塞的CAS(compare-and-swap,比较和交换)原语是不可变的,这样就可以在并发应用程序 中使用该代码而不会出任何问题。
2.3不可变对象
不可变对象是一种非常特殊的对象。在其初始化后,不能修改其可视状态(其属性值)。如果想修 改一个不可变对象,那么你就必须创建一个新的对象。 不可变对象的主要优点在于它是线程安全的。你可以在并发应用程序中使用它而不会出现任何问 题。 不可变对象的一个例子就是java中的String类。当你给一个String对象赋新值时,会创建一个新的 String对象。
2.4原子操作和原子变量
与应用程序的其他任务相比,原子操作是一种发生在瞬间的操作。在并发应用程序中,可以通过一 个临界段来实现原子操作,以便对整个操作采用同步机制。 原子变量是一种通过原子操作来设置和获取其值的变量。可以使用某种同步机制来实现一个原子变 量,或者也可以使用CAS以无锁方式来实现一个原子变量,而这种方式并不需要任何同步机制。
2.5共享内存与消息传递
任务可以通过两种不同的方式来相互通信。第一种方法是共享内存,通常用于在同一台计算机上运 行多任务的情况。任务在读取和写入值的时候使用相同的内存区域。为了避免出现问题,对该共享内存 的访问必须在一个由同步机制保护的临界段内完成。 另一种同步机制是消息传递,通常用于在不同计算机上运行多任务的情形。当一个任务需要与另一 个任务通信时,它会发送一个遵循预定义协议的消息。如果发送方保持阻塞并等待响应,那么该通信就 是同步的;如果发送方在发送消息后继续执行自己的流程,那么该通信就是异步的。
3. 并发的问题
3.1 数据竞争
如果有两个或者多个任务在临界段之外对一个共享变量进行写入操作,也就是说没有使用任何同步 机制,那么应用程序可能存在数据竞争(也叫做竞争条件)。 在这些情况下,应用程序的最终结果可能取决于任务的执行顺序。
package com.lagou.concurrent.demo; public class ConcurrentDemo { private float myFloat; public void modify(float difference) { float value = this.myFloat; this.myFloat = value + difference; }public static void main(String[] args) { } }
假设有两个不同的任务执行了同一个modify方法。由于任务中语句的执行顺序不同,最终结果也会 不同。 modify方法不是原子的, ConcurrentDemo 也不是线程安全的。
3.2 死锁
当两个(或多个)任务正在等待必须由另一线程释放的某个共享资源,而该线程又正在等待必须由 前述任务之一释放的另一共享资惊时,并发应用程序就出现了死锁。当系统中同时出现如下四种条件 时,就会导致这种情形。我们将其称为Coffman 条件。
- 互斥: 死锁中涉及的资师、必须是不可共享的。一次只有一个任务可以使用该资源。
- 占有并等待条件: 一个任务在占有某一互斥的资源时又请求另一互斥的资源。当它在等待时, 不会释放任何资源。
- 不可剥夺:资源只能被那些持有它们的任务释放。
- 循环等待:任务1正等待任务2 所占有的资源, 而任务2 又正在等待任务3 所占有的资源,以此类推,最终任务n又在等待由任务1所占有的资源,这样就出现了循环等待。
有一些机制可以用来避免死锁。
忽略它们:这是最常用的机制。你可以假设自己的系统绝不会出现死锁,而如果发生死锁,结 果就是你可以停止应用程序并且重新执行它。
检测:系统中有一项专门分析系统状态的任务,可以检测是否发生了死锁。如果它检测到了死 锁,可以采取一些措施来修复该问题,例如,结束某个任务或者强制释放某一资源。
预防:如果你想防止系统出现死锁,就必须预防Coffman 条件中的一条或多条出现。
- 规避:如果你可以在某一任务执行之前得到该任务所使用资源的相关信息,那么死锁是可以规 避的。当一个任务要开始执行时,你可以对系统中空闲的资源和任务所需的资源进行分析,这 样就可以判断任务是否能够开始执行。
3.3 活锁
如果系统中有两个任务,它们总是因对方的行为而改变自己的状态, 那么就出现了活锁。最终结果是它们陷入了状态变更的循环而无法继续向下执行。
例如,有两个任务:任务1和任务2 ,它们都需要用到两个资源:资源1和资源2 。假设任务1对资源1加了一个锁,而任务2 对资源2 加了一个锁。当它们无法访问所需的资源时,就会释放自己的资源并且重新开始循环。这种情况可以无限地持续下去,所以这两个任务都不会结束自己的执行过程。
3.4 资源不足
当某个任务在系统中无法获取维持其继续执行所需的资源时,就会出现资源不足。当有多个任务在 等待某一资源且该资源被释放时,系统需要选择下一个可以使用该资源的任务。如果你的系统中没有设 计良好的算法,那么系统中有些线程很可能要为获取该资源而等待很长时间。
要解决这一问题就要确保公平原则。所有等待某一资源的任务必须在某一给定时间之内占有该资 源。可选方案之一就是实现一个算法,在选择下一个将占有某一资源的任务时,对任务已等待该资源的 时间因素加以考虑。然而,实现锁的公平需要增加额外的开销,这可能会降低程序的吞吐量。
3.5 优先权反转
当一个低优先权的任务持有了一个高优先级任务所需的资源时,就会发生优先权反转。这样的话, 低优先权的任务就会在高优先权的任务之前执行。
4. JMM内存模型
4.1 JMM与happen-before
4.1.1为什么会存在“内存可见性”问题
下图为x86架构下CPU缓存的布局,即在一个CPU 4核下,L1、L2、L3三级缓存与主内存的布局。每个核上面有L1、L2缓存,L3缓存为所有核共用。
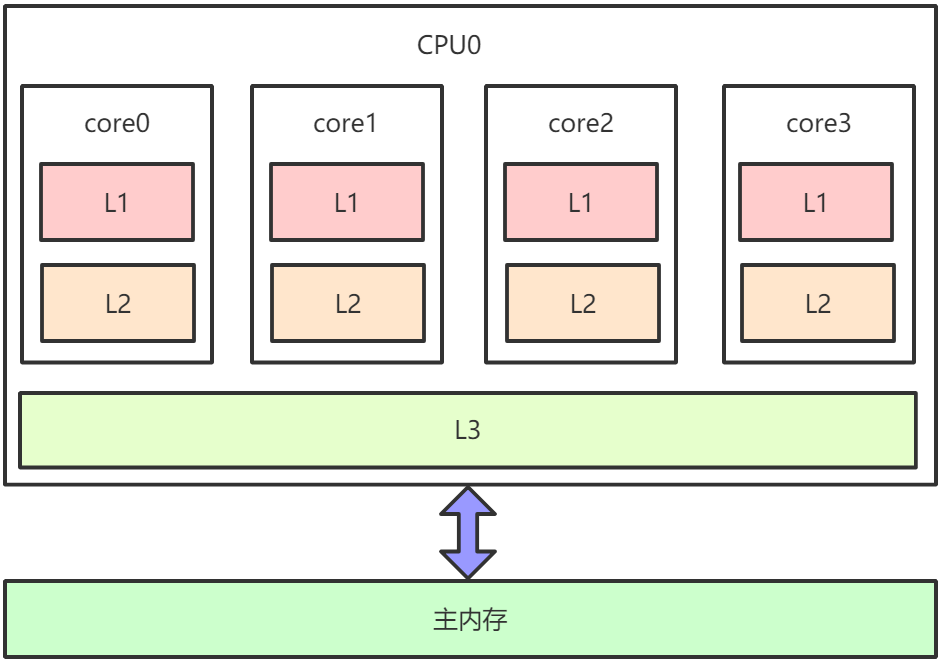
因为存在CPU缓存一致性协议,例如MESI,多个CPU核心之间缓存不会出现不同步的问题,不会有 “内存可见性”问题。 缓存一致性协议对性能有很大损耗,为了解决这个问题,又进行了各种优化。例如,在计算单元和 L1之间加了Store Buffer、Load Buffer(还有其他各种Buffer),如下图:
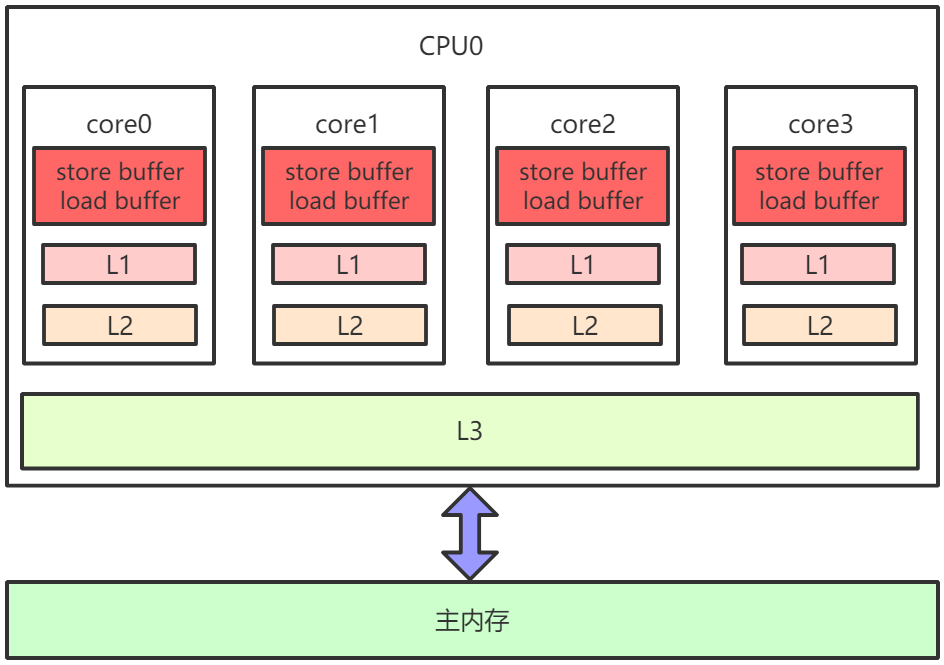
L1、L2、L3和主内存之间是同步的,有缓存一致性协议的保证,但是Store Buffer、Load Buffer和L1之间却是异步的。向内存中写入一个变量,这个变量会保存在Store Buffer里面,稍后才异步地写入L1中,同时同步写入主内存中。 操作系统内核视角下的CPU缓存模型:
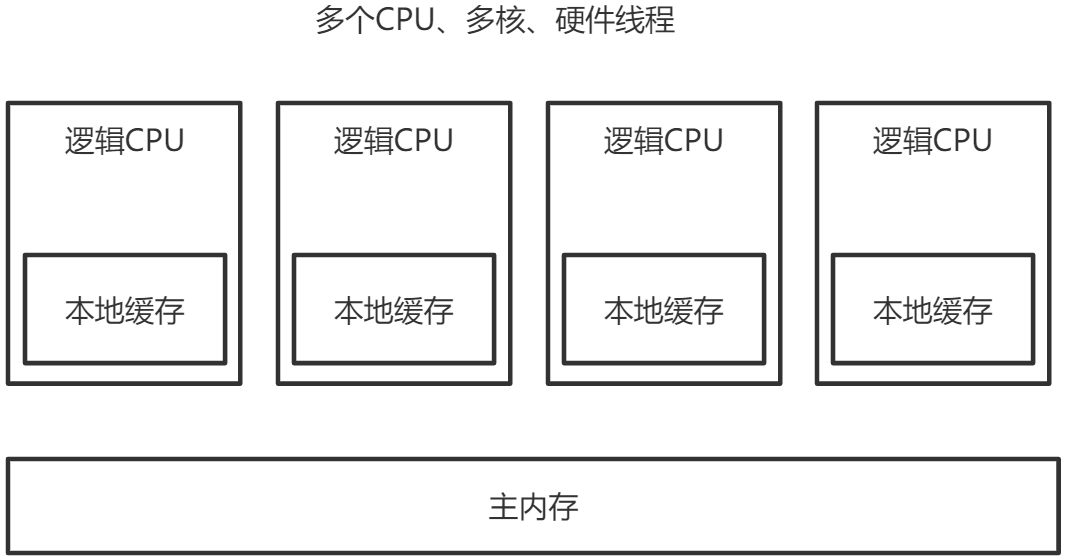
多CPU,每个CPU多核,每个核上面可能还有多个硬件线程,对于操作系统来讲,就相当于一个个 的逻辑CPU。每个逻辑CPU都有自己的缓存,这些缓存和主内存之间不是完全同步的。 对应到Java里,就是JVM抽象内存模型,如下图所示:
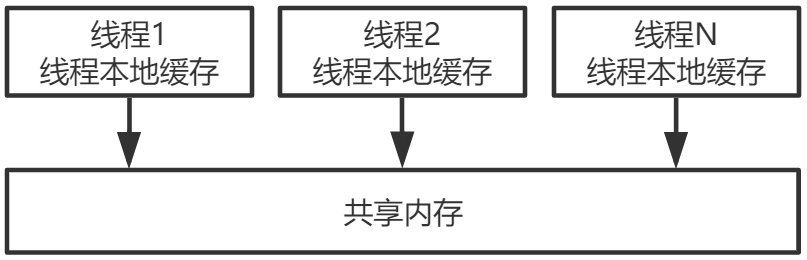
4.1.2重排序与内存可见性的关系
Store Buffer的延迟写入是重排序的一种,称为内存重排序(Memory Ordering)。除此之外,还有编译器和CPU的指令重排序。 重排序类型:
编译器重排序。 对于没有先后依赖关系的语句,编译器可以重新调整语句的执行顺序。
CPU指令重排序。 在指令级别,让没有依赖关系的多条指令并行。
CPU内存重排序。 CPU有自己的缓存,指令的执行顺序和写入主内存的顺序不完全一致。
在三种重排序中,第三类就是造成“内存可见性”问题的主因,如下案例:
线程1: X=1 a=Y 线程2: Y=1 b=X
假设X、Y是两个全局变量,初始的时候,X=0,Y=0。请问,这两个线程执行完毕之后,a、b的正 确结果应该是什么? 很显然,线程1和线程2的执行先后顺序是不确定的,可能顺序执行,也可能交叉执行,最终正确的 结果可能是:
- a=0,b=1
- a=1,b=0
- a=1,b=1
也就是不管谁先谁后,执行结果应该是这三种场景中的一种。但实际可能是a=0,b=0。 两个线程的指令都没有重排序,执行顺序就是代码的顺序,但仍然可能出现a=0,b=0。原因是线程 1先执行X=1,后执行a=Y,但此时X=1还在自己的Store Buffer里面,没有及时写入主内存中。所以,线程2看到的X还是0。线程2的道理与此相同。 虽然线程1觉得自己是按代码顺序正常执行的,但在线程2看来,a=Y和X=1顺序却是颠倒的。指令没 有重排序,是写入内存的操作被延迟了,也就是内存被重排序了,这就造成内存可见性问题。
4.1.3内存屏障
为了禁止编译器重排序和 CPU 重排序,在编译器和 CPU 层面都有对应的指令,也就是内存屏障 (Memory Barrier)。这也正是JMM和happen-before规则的底层实现原理。 编译器的内存屏障,只是为了告诉编译器不要对指令进行重排序。当编译完成之后,这种内存屏障 就消失了,CPU并不会感知到编译器中内存屏障的存在。 而CPU的内存屏障是CPU提供的指令,可以由开发者显示调用。
内存屏障是很底层的概念,对于 Java 开发者来说,一般用 volatile 关键字就足够了。但从JDK 8开始,Java在Unsafe类中提供了三个内存屏障函数,如下所示。
public final class Unsafe { // ...
public native void loadFence(); public native void storeFence(); public native void fullFence(); // ... }
在理论层面,可以把基本的CPU内存屏障分成四种:
1.LoadLoad:禁止读和读的重排序。 2.StoreStore:禁止写和写的重排序。 3.LoadStore:禁止读和写的重排序。 4.StoreLoad:禁止写和读的重排序。
Unsafe中的方法:
1.loadFence=LoadLoad+LoadStore 2.storeFence=StoreStore+LoadStore 3.fullFence=loadFence+storeFence+StoreLoad
4.1.4 as-if-serial语义
重排序的原则是什么?什么场景下可以重排序,什么场景下不能重排序呢? 1.单线程程序的重排序规则 无论什么语言,站在编译器和CPU的角度来说,不管怎么重排序,单线程程序的执行结果不能改 变,这就是单线程程序的重排序规则。 即只要操作之间没有数据依赖性,编译器和CPU都可以任意重排序,因为执行结果不会改变,代码 看起来就像是完全串行地一行行从头执行到尾,这也就是as-if-serial语义。 对于单线程程序来说,编译器和CPU可能做了重排序,但开发者感知不到,也不存在内存可见性问 题。 2.多线程程序的重排序规则 编译器和CPU的这一行为对于单线程程序没有影响,但对多线程程序却有影响。 对于多线程程序来说,线程之间的数据依赖性太复杂,编译器和CPU没有办法完全理解这种依赖性 并据此做出最合理的优化。 编译器和CPU只能保证每个线程的as-if-serial语义。 线程之间的数据依赖和相互影响,需要编译器和CPU的上层来确定。 上层要告知编译器和CPU在多线程场景下什么时候可以重排序,什么时候不能重排序。
4.1.5happen-before是什么
使用happen-before描述两个操作之间的内存可见性。
java内存模型(JMM)是一套规范,在多线程中,一方面,要让编译器和CPU可以灵活地重排序; 另一方面,要对开发者做一些承诺,明确告知开发者不需要感知什么样的重排序,需要感知什么样的重 排序。然后,根据需要决定这种重排序对程序是否有影响。如果有影响,就需要开发者显示地通过volatile、synchronized等线程同步机制来禁止重排序。 关于happen-before: 如果A happen-before B,意味着A的执行结果必须对B可见,也就是保证跨线程的内存可见性。A happen before B不代表A一定在B之前执行。因为,对于多线程程序而言,两个操作的执行顺序是不确定的。happen-before只确保如果A在B之前执行,则A的执行结果必须对B可见。定义了内存可见性的约 束,也就定义了一系列重排序的约束。 基于happen-before的这种描述方法,JMM对开发者做出了一系列承诺: 1.单线程中的每个操作,happen-before 对应该线程中任意后续操作(也就是 as-if-serial语义保证)。 2.对volatile变量的写入,happen-before对应后续对这个变量的读取。 3.对synchronized的解锁,happen-before对应后续对这个锁的加锁。 …… JMM对编译器和CPU 来说,volatile 变量不能重排序;非 volatile 变量可以任意重排序。
4.1.6happen-before的传递性
除了这些基本的happen-before规则,happen-before还具有传递性,即若A happen-before B,B happen-before C,则A happen-before C。 如果一个变量不是volatile变量,当一个线程读取、一个线程写入时可能有问题。那岂不是说,在多 线程程序中,我们要么加锁,要么必须把所有变量都声明为volatile变量?这显然不可能,而这就得归功 于happen-before的传递性。
class A { private int a = 0; private volatile int c = 0; public void set() { a = 5; // 操作1 c = 1; // 操作2 }public int get() { int d = c; // 操作3 return a; // 操作4 } }
假设线程A先调用了set,设置了a=5;之后线程B调用了get,返回值一定是a=5。为什么呢? 操作1和操作2是在同一个线程内存中执行的,操作1 happen-before 操作2,同理,操作3 happen- before操作4。又因为c是volatile变量,对c的写入happen-before对c的读取,所以操作2 happen- before操作3。利用happen-before的传递性,就得到: 操作1 happen-before 操作2 happen-before 操作3 happen-before操作4。所以,操作1的结果,一定对操作4可见。
class A { private int a = 0; private int c = 0; public synchronized void set() { a = 5; // 操作1 c = 1; // 操作2
}public synchronized int get() { return a; } }
假设线程A先调用了set,设置了a=5;之后线程B调用了get,返回值也一定是a=5。 因为与volatile一样,synchronized同样具有happen-before语义。展开上面的代码可得到类似于下 面的伪代码:
线程A:
加锁; // 操作1
a = 5; // 操作2
c = 1; // 操作3
解锁; // 操作4
线程B:
加锁; // 操作5
读取a; // 操作6
解锁; // 操作7
根据synchronized的happen-before语义,操作4 happen-before 操作5,再结合传递性,最终就会得到: 操作1 happen-before 操作2……happen-before 操作7。所以,a、c都不是volatile变量,但仍然有内存可见性。
4.2 volatile关键字
4.2.164位写入的原子性(Half Write)
如,对于一个long型变量的赋值和取值操作而言,在多线程场景下,线程A调用set(100),线程B调 用get(),在某些场景下,返回值可能不是100。
public class MyClass {
private long a = 0; // 线程A调用set(100)
public void set(long a) { this.a = a; }
// 线程B调用get(),返回值一定是100吗?
public long get() { return this.a; }
}
因为JVM的规范并没有要求64位的long或者double的写入是原子的。在32位的机器上,一个64位变 量的写入可能被拆分成两个32位的写操作来执行。这样一来,读取的线程就可能读到“一半的值”。解决 办法也很简单,在long前面加上volatile关键字。
4.2.2 重排序:DCL问题
单例模式的线程安全的写法不止一种,常用写法为DCL(Double Checking Locking),如下所示:
public class Singleton { private static Singleton instance; public static Singleton getInstance() { if (instance == null) { synchronized(Singleton.class) { if (instance == null) { // 此处代码有问题
instance = new Singleton(); } } }return instance; } }
上述的instance = new Singleton(); 代码有问题:其底层会分为三个操作: 1.分配一块内存。 2.在内存上初始化成员变量。 3.把instance引用指向内存。 在这三个操作中,操作2和操作3可能重排序,即先把instance指向内存,再初始化成员变量,因为 二者并没有先后的依赖关系。此时,另外一个线程可能拿到一个未完全初始化的对象。这时,直接访问 里面的成员变量,就可能出错。这就是典型的“构造方法溢出”问题。 解决办法也很简单,就是为instance变量加上volatile修饰。 volatile的三重功效:64位写入的原子性、内存可见性和禁止重排序。
4.2.3 volatile实现原理
由于不同的CPU架构的缓存体系不一样,重排序的策略不一样,所提供的内存屏障指令也就有差 异。 这里只探讨为了实现volatile关键字的语义的一种参考做法: 1.在volatile写操作的前面插入一个StoreStore屏障。保证volatile写操作不会和之前的写操作重 排序。 2.在volatile写操作的后面插入一个StoreLoad屏障。保证volatile写操作不会和之后的读操作重 排序。 3.在volatile读操作的后面插入一个LoadLoad屏障+LoadStore屏障。保证volatile读操作不会和 之后的读操作、写操作重排序。 具体到x86平台上,其实不会有LoadLoad、LoadStore和StoreStore重排序,只有StoreLoad一种 重排序(内存屏障),也就是只需要在volatile写操作后面加上StoreLoad屏障。
4.2.4 JSR-133对volatile语义的增强
在JSR -133之前的旧内存模型中,一个64位long/ double型变量的读/ 写操作可以被拆分为两个32位的读/写操作来执行。从JSR -133内存模型开始 (即从JDK5开始),仅仅只允许把一个64位long/ double 型变量的写操作拆分为两个32位的写操作来执行,任意的读操作在JSR -133中都必须具有原子性(即 任意读操作必须要在单个读事务中执行)。 这也正体现了Java对happen-before规则的严格遵守。
4.3 final关键字
4.3.1构造方法溢出问题
考虑下面的代码:
public class MyClass { private int num1; private int num2; private static MyClass myClass; public MyClass() { num1 = 1; num2 = 2; }/*** 线程A先执行write() */ public static void write() { myClass = new MyClass(); }/*** 线程B接着执行write() */ public static void read() { if (myClass != null) { int num3 = myClass.num1;
int num4 = myClass.num2; } } }
num3和num4的值是否一定是1和2? num3、num4不见得一定等于1,2。和DCL的例子类似,也就是构造方法溢出问题。myClass = new MyClass()这行代码,分解成三个操作: 1.分配一块内存; 2.在内存上初始化i=1,j=2; 3.把myClass指向这块内存。 操作2和操作3可能重排序,因此线程B可能看到未正确初始化的值。对于构造方法溢出,就是一个 对象的构造并不是“原子的”,当一个线程正在构造对象时,另外一个线程却可以读到未构造好的“一半对 象”。
4.3.2 final的happen-before语义
要解决这个问题,不止有一种办法。 办法1:给num1,num2加上volatile关键字。 办法2:为read/write方法都加上synchronized关键字。 如果num1,num2只需要初始化一次,还可以使用final关键字。 之所以能解决问题,是因为同volatile一样,final关键字也有相应的happen-before语义: 1.对final域的写(构造方法内部),happen-before于后续对final域所在对象的读。 2.对final域所在对象的读,happen-before于后续对final域的读。 通过这种happen-before语义的限定,保证了final域的赋值,一定在构造方法之前完成,不会出现 另外一个线程读取到了对象,但对象里面的变量却还没有初始化的情形,避免出现构造方法溢出的问 题。
4.3.3 happen-before规则总结
1.单线程中的每个操作,happen-before于该线程中任意后续操作。 2.对volatile变量的写,happen-before于后续对这个变量的读。 3.对synchronized的解锁,happen-before于后续对这个锁的加锁。 4.对final变量的写,happen-before于final域对象的读,happen-before于后续对final变量的 读。 四个基本规则再加上happen-before的传递性,就构成JMM对开发者的整个承诺。在这个承诺以外 的部分,程序都可能被重排序,都需要开发者小心地处理内存可见性问题。
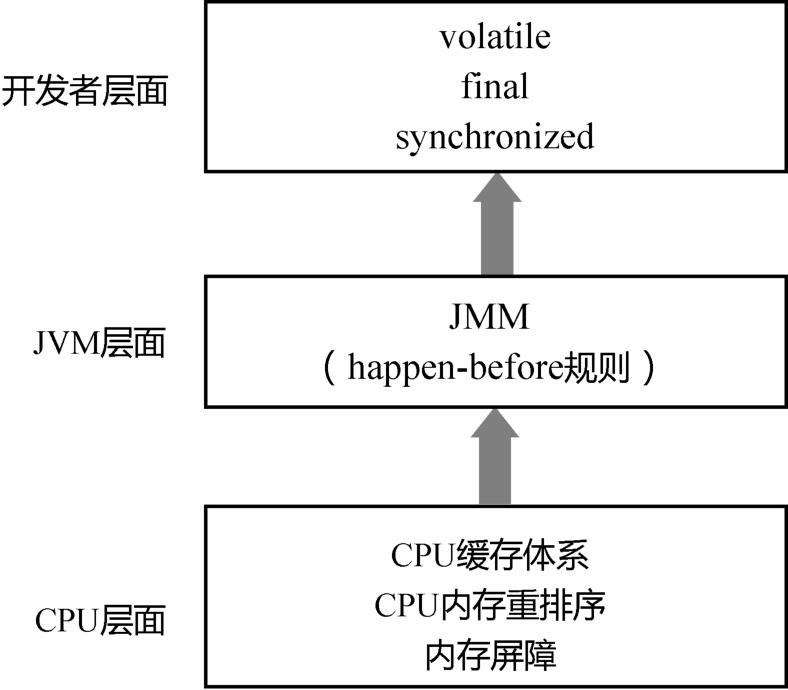
第二部分:JUC
5并发容器
5.1 BlockingQueue
在所有的并发容器中,BlockingQueue是最常见的一种。BlockingQueue是一个带阻塞功能的队 列,当入队列时,若队列已满,则阻塞调用者;当出队列时,若队列为空,则阻塞调用者。
在Concurrent包中,BlockingQueue是一个接口,有许多个不同的实现类,如图所示。
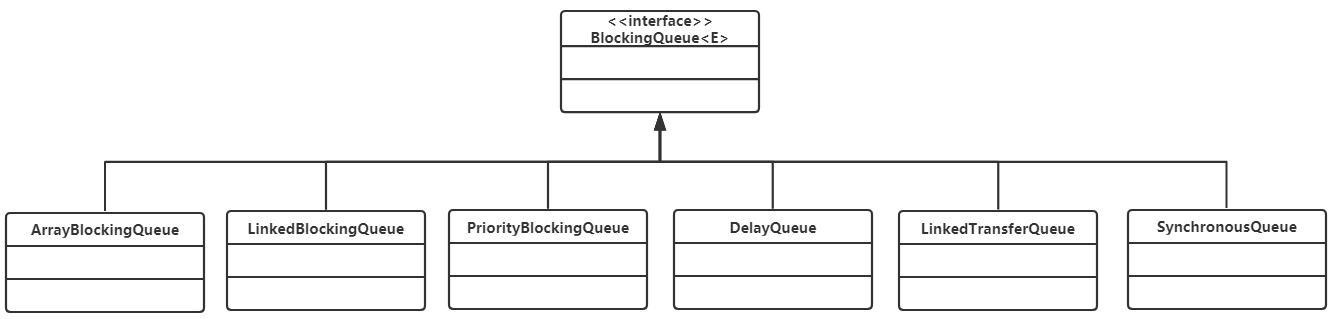
该接口的定义如下:
public interface BlockingQueue<E> extends Queue<E> { //...
boolean add(E e); boolean offer(E e); void put(E e) throws InterruptedException; boolean remove(Object o); E take() throws InterruptedException; E poll(long timeout, TimeUnit unit) throws InterruptedException;
//...
}
该接口和JDK集合包中的Queue接口是兼容的,同时在其基础上增加了阻塞功能。在这里,入队提 供了add(...)、offer(..)、put(...)3个方法,有什么区别呢?从上面的定义可以看到,add(...)和offer(..)的 返回值是布尔类型,而put无返回值,还会抛出中断异常,所以add(...)和offer(..)是无阻塞的,也是Queue本身定义的接口,而put(..)是阻塞的。add(...)和offer(..)的区别不大,当队列为满的时候,前者会 抛出异常,后者则直接返回false。 出队列与之类似,提供了remove()、poll()、take()等方法,remove()是非阻塞式的,take()和poll() 是阻塞式的。
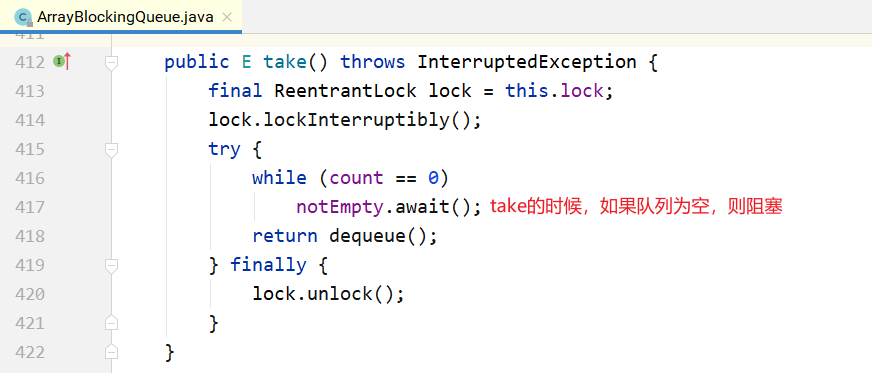
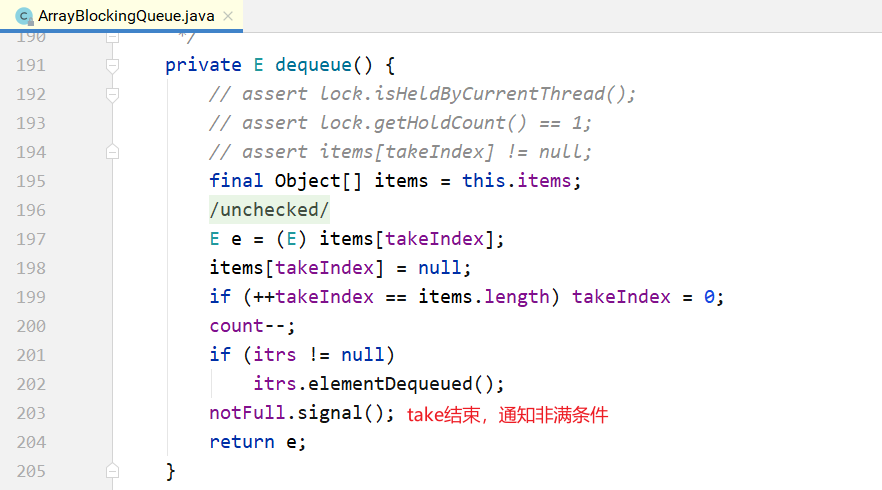
5.1.1ArrayBlockingQueue
ArrayBlockingQueue是一个用数组实现的环形队列,在构造方法中,会要求传入数组的容量。
public ArrayBlockingQueue(int capacity) { this(capacity, false); }public ArrayBlockingQueue(int capacity, boolean fair) {
// ...
}public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c) { this(capacity, fair);
// ...
}
其核心数据结构如下:
public class ArrayBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable { //...
final Object[] items; // 队头指针
int takeIndex; // 队尾指针
int putIndex; int count;
// 核心为1个锁外加两个条件
final ReentrantLock lock;
private final Condition notEmpty;
private final Condition notFull;
//...
}
其put/take方法也很简单,如下所示。 put方法:


take方法:
5.1.2 LinkedBlockingQueue
LinkedBlockingQueue是一种基于单向链表的阻塞队列。因为队头和队尾是2个指针分开操作的, 所以用了2把锁+2个条件,同时有1个AtomicInteger的原子变量记录count数。
public class LinkedBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
// ...
private final int capacity;
// 原子变量
private final AtomicInteger count = new AtomicInteger(0);
// 单向链表的头部
private transient Node<E> head;
// 单向链表的尾部
private transient Node<E> last;
// 两把锁,两个条件
private final ReentrantLock takeLock = new ReentrantLock();
private final Condition notEmpty = takeLock.newCondition();
private final ReentrantLock putLock = new ReentrantLock();
private final Condition notFUll = putLock.newCondition();
// ...
}
在其构造方法中,也可以指定队列的总容量。如果不指定,默认为Integer.MAX_VALUE。

put/take实现。
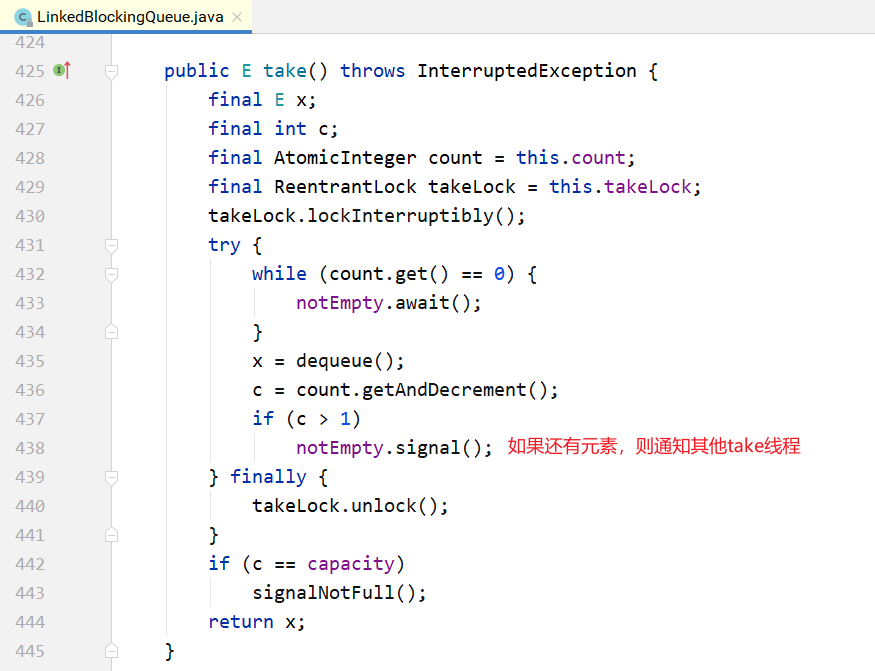
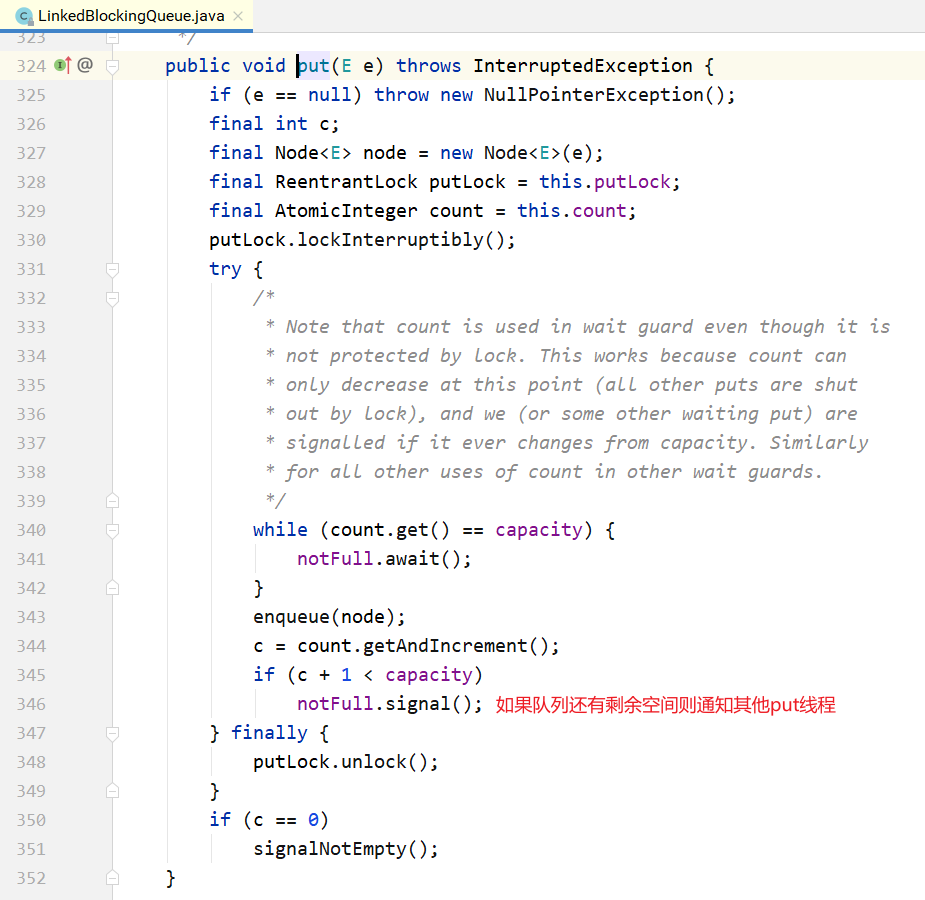
LinkedBlockingQueue和ArrayBlockingQueue的差异: 1.为了提高并发度,用2把锁,分别控制队头、队尾的操作。意味着在put(...)和put(...)之间、take()与take()之间是互斥的,put(...)和take()之间并不互斥。但对于count变量,双方都需要 操作,所以必须是原子类型。 2.因为各自拿了一把锁,所以当需要调用对方的condition的signal时,还必须再加上对方的锁, 就是signalNotEmpty()和signalNotFull()方法。示例如下所示。
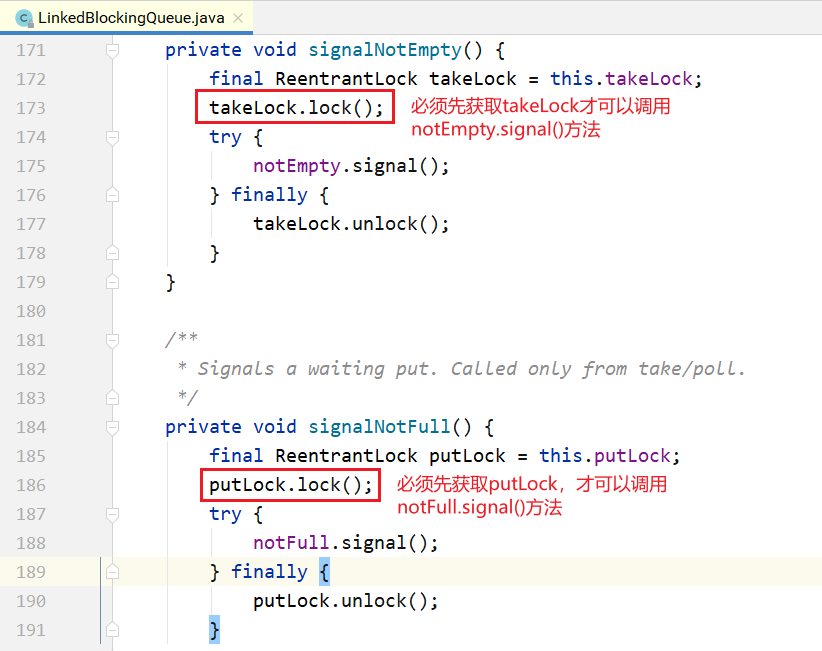
3.不仅put会通知 take,take 也会通知 put。当put 发现非满的时候,也会通知其他 put线程; 当take发现非空的时候,也会通知其他take线程。
5.1.3PriorityBlockingQueue
队列通常是先进先出的,而PriorityQueue是按照元素的优先级从小到大出队列的。正因为如此, PriorityQueue中的2个元素之间需要可以比较大小,并实现Comparable接口。
其核心数据结构如下:
public class PriorityBlockingQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable {
//... // 用数组实现的二插小根堆
private transient Object[] queue; private transient int size;
private transient Comparator<? super E> comparator;
// 1个锁+一个条件,没有非满条件
private final ReentrantLock lock; private final Condition notEmpty;
//...
}
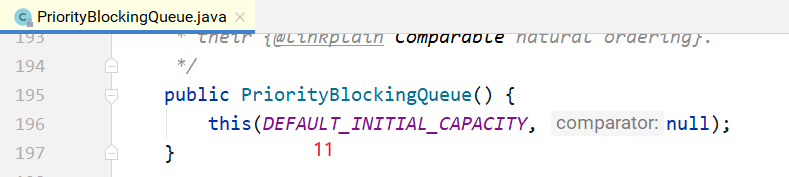
其构造方法如下所示,如果不指定初始大小,内部会设定一个默认值11,当元素个数超过这个大小 之后,会自动扩容。

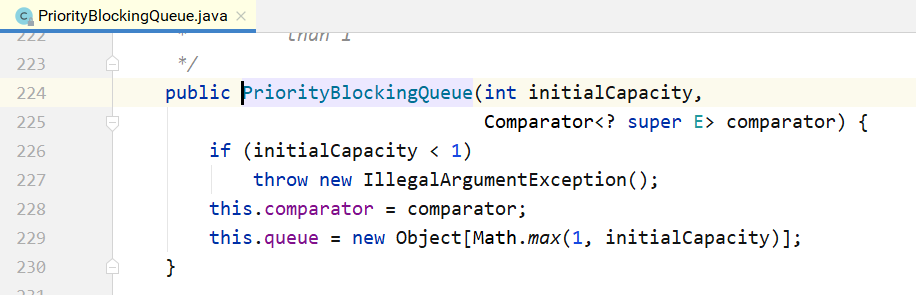
下面是对应的put/take方法的实现。 put方法的实现:
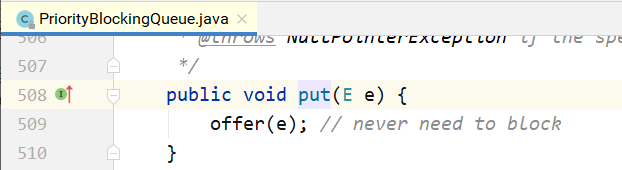
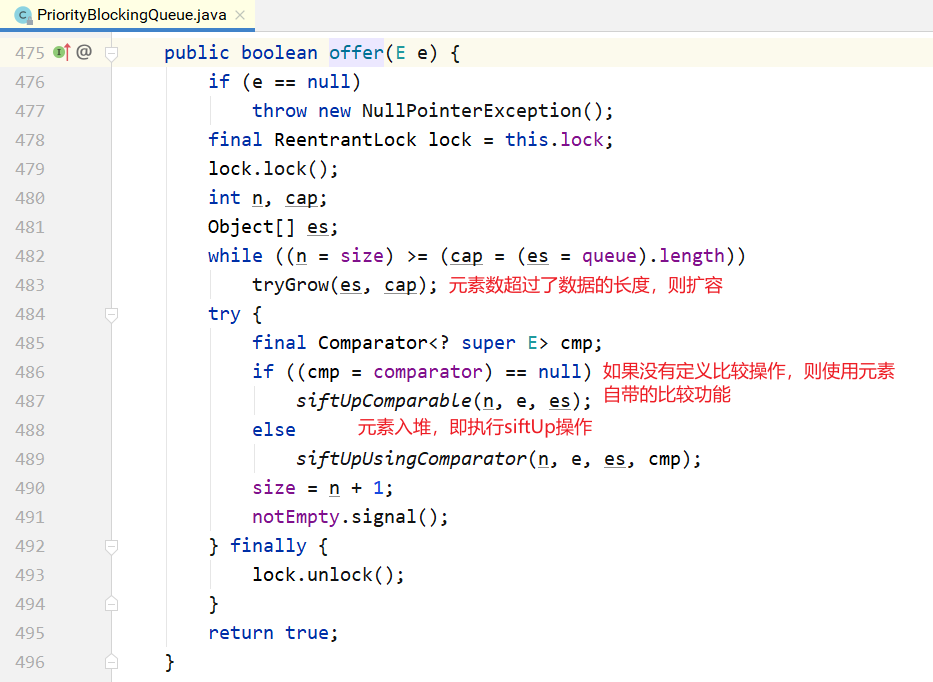
take的实现:

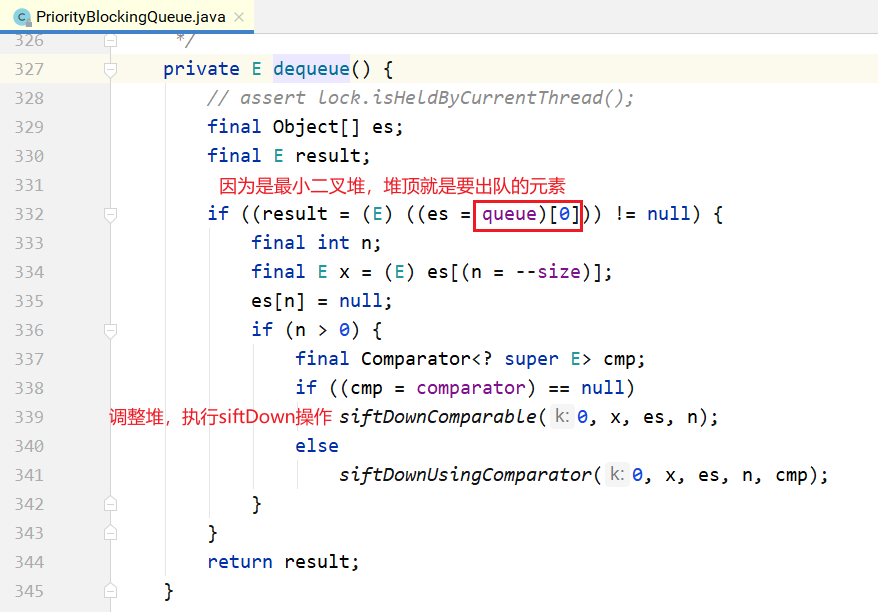
从上面可以看到,在阻塞的实现方面,和ArrayBlockingQueue的机制相似,主要区别是用数组实现 了一个二叉堆,从而实现按优先级从小到大出队列。另一个区别是没有notFull条件,当元素个数超出数 组长度时,执行扩容操作。
5.1.4 DelayQueue
DelayQueue即延迟队列,也就是一个按延迟时间从小到大出队的PriorityQueue。所谓延迟时间, 就是“未来将要执行的时间”减去“当前时间”。为此,放入DelayQueue中的元素,必须实现Delayed接 口,如下所示。
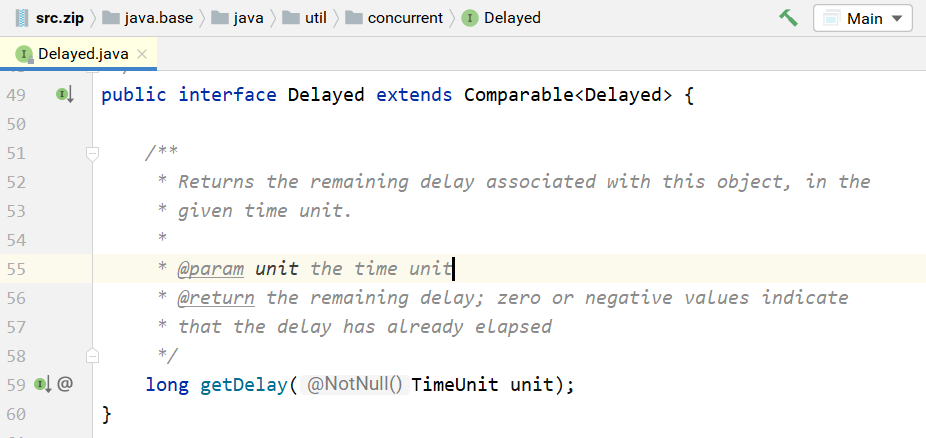
关于该接口: 1.如果getDelay的返回值小于或等于0,则说明该元素到期,需要从队列中拿出来执行。
2.该接口首先继承了 Comparable 接口,所以要实现该接口,必须实现 Comparable 接口。具体来说,就是基于getDelay()的返回值比较两个元素的大小。
下面看一下DelayQueue的核心数据结构。
public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements BlockingQueue<E> {
// ...
// 一把锁和一个非空条件
private final transient ReentrantLock lock = new ReentrantLock();
private final Condition available = lock.newCondition();
// 优先级队列
private final PriorityQueue<E> q = new PriorityQueue<E>();
// ...
}
下面介绍put/take的实现,先从take说起,因为这样更能看出DelayQueue的特性。


关于take()方法: 1.不同于一般的阻塞队列,只在队列为空的时候,才阻塞。如果堆顶元素的延迟时间没到,也会 阻塞。 2.在上面的代码中使用了一个优化技术,用一个Thread leader变量记录了等待堆顶元素的第1个线程。为什么这样做呢?通过 getDelay(..)可以知道堆顶元素何时到期,不必无限期等待,可以使用condition.awaitNanos()等待一个有限的时间;只有当发现还有其他线程也在等待堆顶 元素(leader!=NULL)时,才需要无限期等待。
put的实现:
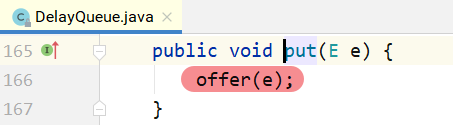
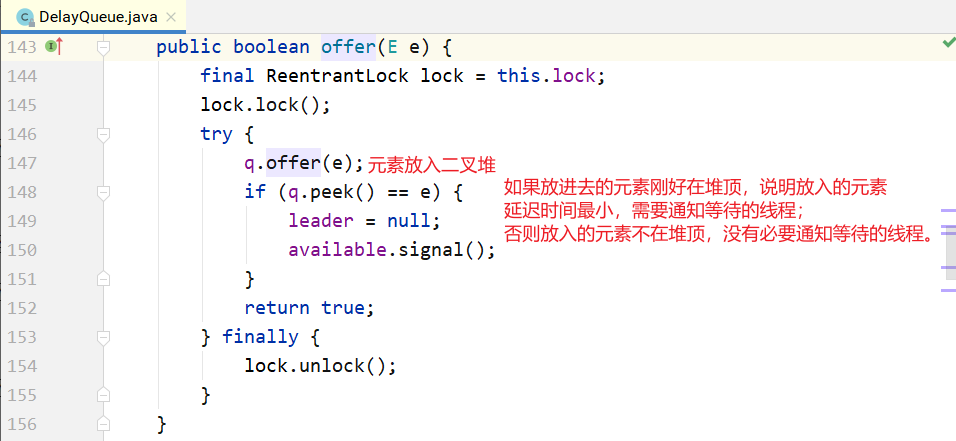
注意:不是每放入一个元素,都需要通知等待的线程。放入的元素,如果其延迟时间大于当前堆顶 的元素延迟时间,就没必要通知等待的线程;只有当延迟时间是最小的,在堆顶时,才有必要通知等待 的线程,也就是上面代码中的 部分。
5.1.5 SynchronousQueue
SynchronousQueue是一种特殊的BlockingQueue,它本身没有容量。先调put(...),线程会阻塞; 直到另外一个线程调用了take(),两个线程才同时解锁,反之亦然。对于多个线程而言,例如3个线程, 调用3次put(...),3个线程都会阻塞;直到另外的线程调用3次take(),6个线程才同时解锁,反之亦然。
接下来看SynchronousQueue的实现。
构造方法:

和锁一样,也有公平和非公平模式。如果是公平模式,则用TransferQueue实现;如果是非公平模 式,则用TransferStack实现。这两个类分别是什么呢?先看一下put/take的实现。
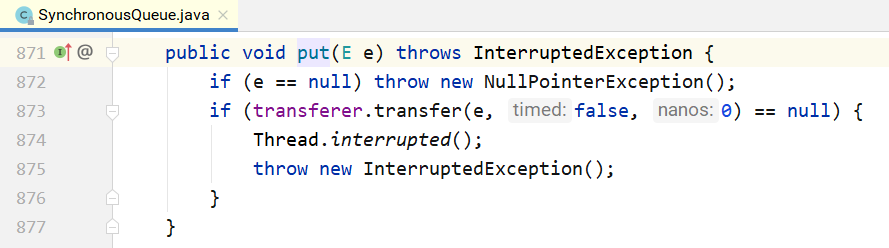
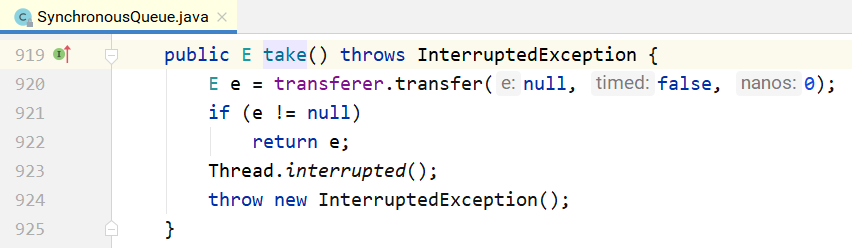
可以看到,put/take都调用了transfer(...)接口。而TransferQueue和TransferStack分别实现了这个 接口。该接口在SynchronousQueue内部,如下所示。如果是put(...),则第1个参数就是对应的元素; 如果是take(),则第1个参数为null。后2个参数分别为是否设置超时和对应的超时时间。
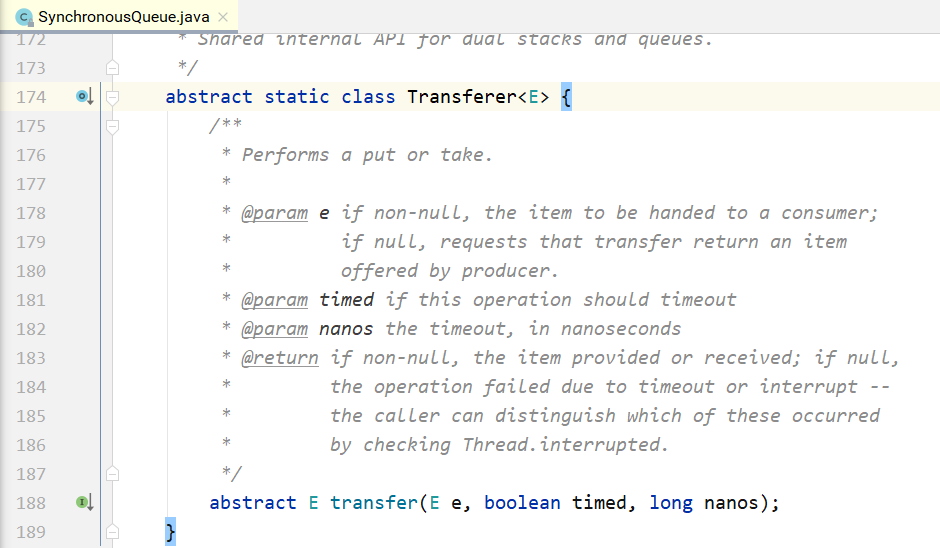
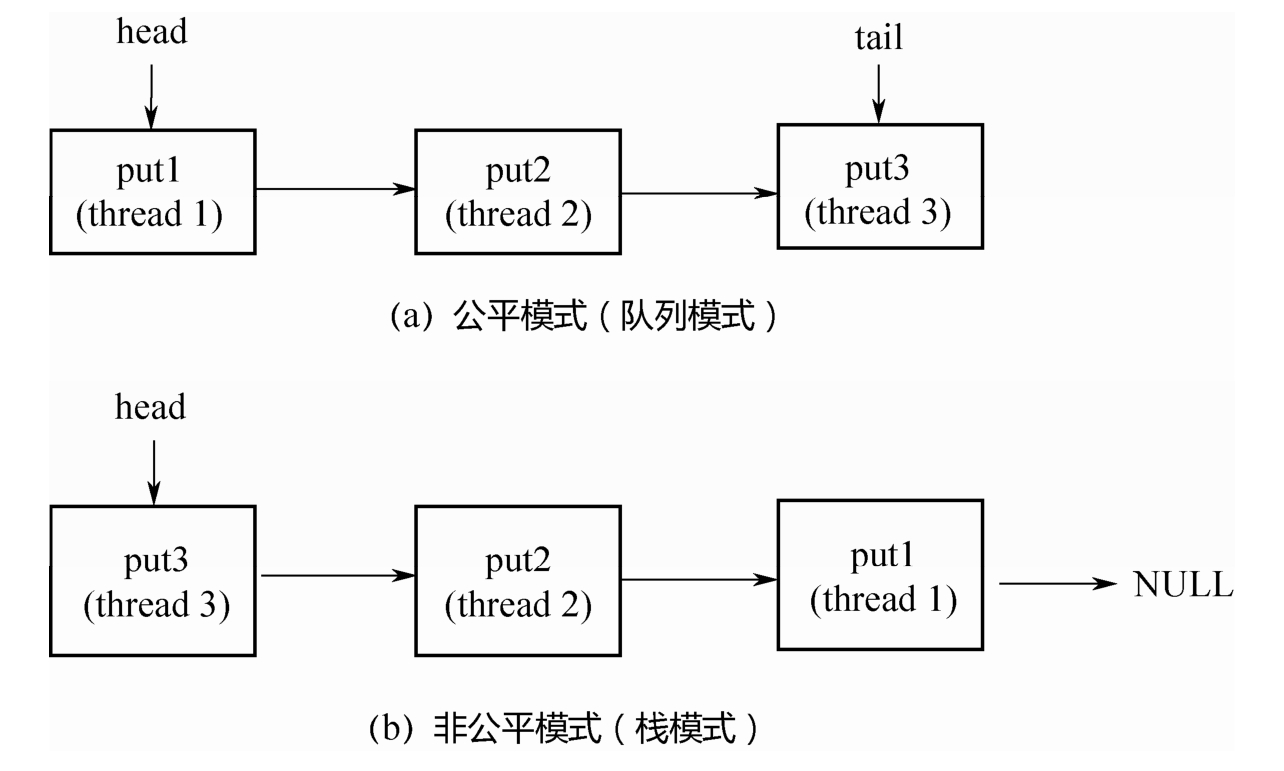
接下来看一下什么是公平模式和非公平模式。假设3个线程分别调用了put(...),3个线程会进入阻塞 状态,直到其他线程调用3次take(),和3个put(...)一一配对。
如果是公平模式(队列模式),则第1个调用put(...)的线程1会在队列头部,第1个到来的take()线程 和它进行配对,遵循先到先配对的原则,所以是公平的;如果是非公平模式(栈模式),则第3个调用put(...)的线程3会在栈顶,第1个到来的take()线程和它进行配对,遵循的是后到先配对的原则,所以是 非公平的。
下面分别看一下TransferQueue和TransferStack的实现。 1.TransferQueue
public class SynchronousQueue<E> extends AbstractQueue<E> implements BlockingQueue<E>, java.io.Serializable { // ...
static final class TransferQueue<E> extends Transferer<E> { static final class QNode { volatile QNode next; volatile Object item; volatile Thread waiter; final boolean isData; //...
}transient volatile QNode head; transient volatile QNode tail;
// ...
}
}
从上面的代码可以看出,TransferQueue是一个基于单向链表而实现的队列,通过head和tail 2个指针记录头部和尾部。初始的时候,head和tail会指向一个空节点,构造方法如下所示。
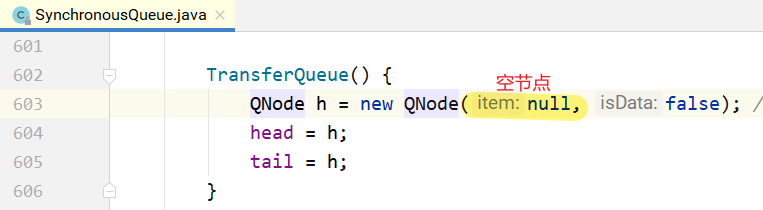
阶段(a):队列中是一个空的节点,head/tail都指向这个空节点。阶段(b):3个线程分别调用put,生成3个QNode,进入队列。 阶段(c):来了一个线程调用take,会和队列头部的第1个QNode进行配对。 阶段(d):第1个QNode出队列。

这里有一个关键点:put节点和take节点一旦相遇,就会配对出队列,所以在队列中不可能同时存在 put节点和take节点,要么所有节点都是put节点,要么所有节点都是take节点。
接下来看一下TransferQueue的代码实现。

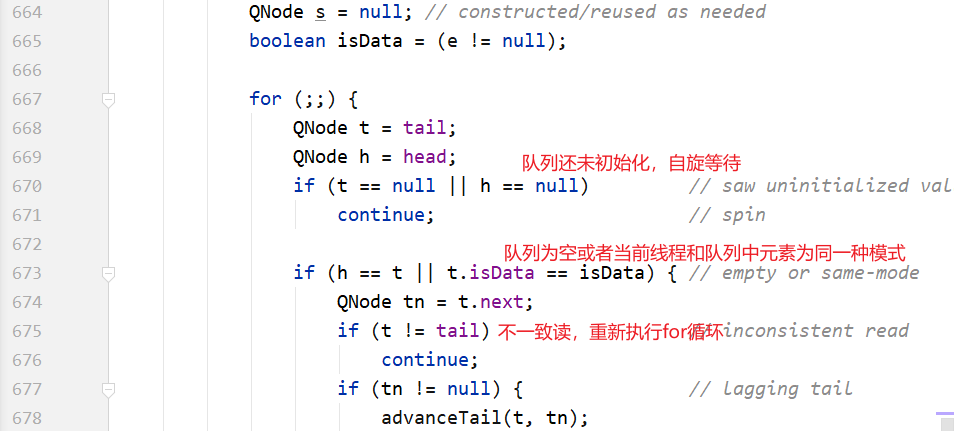


整个 for 循环有两个大的 if-else 分支,如果当前线程和队列中的元素是同一种模式(都是put节点或者take节点),则与当前线程对应的节点被加入队列尾部并且阻塞;如果不是同一种模式,则选取队 列头部的第1个元素进行配对。
这里的配对就是m.casItem(x,e),把自己的item x换成对方的item e,如果CAS操作成功,则配对成功。如果是put节点,则isData=true,item!=null;如果是take节点,则isData=false, item=null。如果CAS操作不成功,则isData和item之间将不一致,也就是isData!=(x!=null),通过 这个条件可以判断节点是否已经被匹配过了。
2.TransferStack
TransferStack的定义如下所示,首先,它也是一个单向链表。不同于队列,只需要head指针就能 实现入栈和出栈操作。
static final class TransferStack extends Transferer { static final int REQUEST = 0; static final int DATA = 1; static final int FULFILLING = 2; static final class SNode { volatile SNode next; // 单向链表 volatile SNode match; // 配对的节点 volatile Thread waiter; // 对应的阻塞线程 Object item; int mode; // 三种模式 //... }volatile SNode head; }
链表中的节点有三种状态,REQUEST对应take节点,DATA对应put节点,二者配对之后,会生成一 个FULFILLING节点,入栈,然后FULLING节点和被配对的节点一起出栈。
阶段(a):head指向NULL。不同于TransferQueue,这里没有空的头节点。
阶段(b):3个线程调用3次put,依次入栈。 阶段(c):线程4调用take,和栈顶的第1个元素配对,生成FULLFILLING节点,入栈。 阶段(d):栈顶的2个元素同时入栈。

下面看一下具体的代码实现。




5.2 BlockingDeque
BlockingDeque定义了一个阻塞的双端队列接口,如下所示。
public interface BlockingDeque<E> extends BlockingQueue<E>, Deque<E> { void putFirst(E e) throws InterruptedException; void putLast(E e) throws InterruptedException; E takeFirst() throws InterruptedException; E takeLast() throws InterruptedException; // ... }
该接口继承了BlockingQueue接口,同时增加了对应的双端队列操作接口。该接口只有一个实现, 就是LinkedBlockingDeque。
其核心数据结构如下所示,是一个双向链表。
public class LinkedBlockingDeque<E> extends AbstractQueue<E> implements BlockingDeque<E>, java.io.Serializable { static final class Node<E> { E item; Node<E> prev; // 双向链表的Node Node<E> next;
Node(E x) { item = x; } }transient Node<E> first; // 队列的头和尾
transient Node<E> last; private transient int count; // 元素个数
private final int capacity; // 容量 // 一把锁+两个条件
final ReentrantLock lock = new ReentrantLock(); private final Condition notEmpty = lock.netCondition(); private final Condition notFull = lock.newCondition(); // ...
}
对应的实现原理,和LinkedBlockingQueue基本一样,只是LinkedBlockingQueue是单向链表,而 LinkedBlockingDeque是双向链表。




5.3 CopyOnWrite
CopyOnWrite指在“写”的时候,不是直接“写”源数据,而是把数据拷贝一份进行修改,再通过悲观 锁或者乐观锁的方式写回。 那为什么不直接修改,而是要拷贝一份修改呢? 这是为了在“读”的时候不加锁。
5.3.1CopyOnWriteArrayList
和ArrayList一样,CopyOnWriteArrayList的核心数据结构也是一个数组,代码如下:
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// ...
private volatile transient Object[] array;
}
下面是CopyOnArrayList的几个“读”方法:
final Object[] getArray() { return array; }//
public E get(int index) { return elementAt(getArray(), index); }public boolean isEmpty() { return size() == 0; }public boolean contains(Object o) { return indexOf(o) >= 0; }public int indexOf(Object o) { Object[] es = getArray(); return indexOfRange(o, es, 0, es.length); }private static int indexOfRange(Object o, Object[] es, int from, int to) { if (o == null) { for (int i = from; i < to; i++) if (es[i] == null) return i; } else { for (int i = from; i < to; i++) if (o.equals(es[i])) return i; }return -1; }
既然这些“读”方法都没有加锁,那么是如何保证“线程安全”呢?答案在“写”方法里面。
public class CopyOnWriteArrayList<E> implements List<E>, RandomAccess, Cloneable, java.io.Serializable { // 锁对象 final transient Object lock = new Object(); public boolean add(E e) { synchronized (lock) { // 同步锁对象 Object[] es = getArray(); int len = es.length; es = Arrays.copyOf(es, len + 1); // CopyOnWrite,写的时候,先拷贝一 份之前的数组。 es[len] = e; setArray(es); return true; } }public void add(int index, E element) { synchronized (lock) { // 同步锁对象 Object[] es = getArray(); int len = es.length; if (index > len || index < 0)
throw new IndexOutOfBoundsException(outOfBounds(index, len)); Object[] newElements; int numMoved = len - index; if (numMoved == 0) newElements = Arrays.copyOf(es, len + 1); else {newElements = new Object[len + 1]; System.arraycopy(es, 0, newElements, 0, index); // CopyOnWrite,写的时候,先拷贝一份之前的数组。 System.arraycopy(es, index, newElements, index + 1, numMoved); }newElements[index] = element; setArray(newElements); // 把新数组赋值给老数组 } } }
其他“写”方法,例如remove和add类似,此处不再详述。
5.3.2CopyOnWriteArraySet
CopyOnWriteArraySet 就是用 Array 实现的一个 Set,保证所有元素都不重复。其内部是封装的一个CopyOnWriteArrayList。
public class CopyOnWriteArraySet<E> extends AbstractSet<E> implements java.io.Serializable { // 新封装的CopyOnWriteArrayList private final CopyOnWriteArrayList<E> al; public CopyOnWriteArraySet() { al = new CopyOnWriteArrayList<E>(); }public boolean add(E e) { return al.addIfAbsent(e); // 不重复的加进去 } }
5.4 ConcurrentLinkedQueue/Deque
AQS内部的阻塞队列实现原理:基于双向链表,通过对head/tail进行CAS操作,实现入队和出队。
ConcurrentLinkedQueue 的实现原理和AQS 内部的阻塞队列类似:同样是基于 CAS,同样是通过head/tail指针记录队列头部和尾部,但还是有稍许差别。
首先,它是一个单向链表,定义如下:
其次,在AQS的阻塞队列中,每次入队后,tail一定后移一个位置;每次出队,head一定后移一个 位置,以保证head指向队列头部,tail指向链表尾部。
但在ConcurrentLinkedQueue中,head/tail的更新可能落后于节点的入队和出队,因为它不是直 接对 head/tail指针进行 CAS操作的,而是对 Node中的 item进行操作。下面进行详细分析:
1.初始化
初始的时候, head 和tail 都指向一个null 节点。对应的代码如下。
2.入队列 代码如下所示。
上面的入队其实是每次在队尾追加2个节点时,才移动一次tail节点。如下图所示: 初始的时候,队列中有1个节点item1,tail指向该节点,假设线程1要入队item2节点: step1:p=tail,q=p.next=NULL. step2:对p的next执行CAS操作,追加item2,成功之后,p=tail。所以上面的casTail方法不会执 行,直接返回。此时tail指针没有变化。
之后,假设线程2要入队item3节点,如下图所示: step3:p=tail,q=p.next. step4:q!=NULL,因此不会入队新节点。p,q都后移1位。 step5:q=NULL,对p的next执行CAS操作,入队item3节点。 step6:p!=t,满足条件,执行上面的casTail操作,tail后移2个位置,到达队列尾部。
最后总结一下入队列的两个关键点: 1.即使tail指针没有移动,只要对p的next指针成功进行CAS操作,就算成功入队列。 2.只有当 p != tail的时候,才会后移tail指针。也就是说,每连续追加2个节点,才后移1次tail指针。即使CAS失败也没关系,可以由下1个线程来移动tail指针。
3.出队列
上面说了入队列之后,tail指针不变化,那是否会出现入队列之后,要出队列却没有元素可出的情况 呢?
出队列的代码和入队列类似,也有p、q2个指针,整个变化过程如图5-8所示。假设初始的时候head 指向空节点,队列中有item1、item2、item3 三个节点。 step1:p=head,q=p.next.p!=q. step2:后移p指针,使得p=q。 step3:出队列。关键点:此处并没有直接删除item1节点,只是把该节点的item通过CAS操作置为 了NULL。 step4:p!=head,此时队列中有了2个 NULL 节点,再前移1次head指针,对其执行updateHead 操作。
最后总结一下出队列的关键点: 1.出队列的判断并非观察 tail 指针的位置,而是依赖于 head 指针后续的节点是否为NULL这一条件。
2.只要对节点的item执行CAS操作,置为NULL成功,则出队列成功。即使head指针没有成功移 动,也可以由下1个线程继续完成。
4.队列判空
因为head/tail 并不是精确地指向队列头部和尾部,所以不能简单地通过比较 head/tail 指针来判断队列是否为空,而是需要从head指针开始遍历,找第1个不为NULL的节点。如果找到,则队列不为空; 如果找不到,则队列为空。代码如下所示:
5.5ConcurrentHashMap HashMap通常的实现方式是“数组+链表”,这种方式被称为“拉链法”。ConcurrentHashMap在这个 基本原理之上进行了各种优化。
首先是所有数据都放在一个大的HashMap中;其次是引入了红黑树。其原理如下图所示:
如果头节点是Node类型,则尾随它的就是一个普通的链表;如果头节点是TreeNode类型,它的后 面就是一颗红黑树,TreeNode是Node的子类。 链表和红黑树之间可以相互转换:初始的时候是链表,当链表中的元素超过某个阈值时,把链表转 换成红黑树;反之,当红黑树中的元素个数小于某个阈值时,再转换为链表。
那为什么要做这种设计呢? 1.使用红黑树,当一个槽里有很多元素时,其查询和更新速度会比链表快很多,Hash冲突的问 题由此得到较好的解决。 2.加锁的粒度,并非整个ConcurrentHashMap,而是对每个头节点分别加锁,即并发度,就是 Node数组的长度,初始长度为16。 3.并发扩容,这是难度最大的。当一个线程要扩容Node数组的时候,其他线程还要读写,因此 处理过程很复杂,后面会详细分析。
由上述对比可以总结出来:这种设计一方面降低了Hash冲突,另一方面也提升了并发度。 下面从构造方法开始,一步步深入分析其实现过程。 1.构造方法分析
在上面的代码中,变量cap就是Node数组的长度,保持为2的整数次方。tableSizeFor(...)方法是根 据传入的初始容量,计算出一个合适的数组长度。具体而言:1.5倍的初始容量+1,再往上取最接近的2 的整数次方,作为数组长度cap的初始值。 这里的 sizeCtl,其含义是用于控制在初始化或者并发扩容时候的线程数,只不过其初始值设置成cap。
2.初始化 在上面的构造方法里只计算了数组的初始大小,并没有对数组进行初始化。当多个线程都往里面放 入元素的时候,再进行初始化。这就存在一个问题:多个线程重复初始化。下面看一下是如何处理的。
通过上面的代码可以看到,多个线程的竞争是通过对sizeCtl进行CAS操作实现的。如果某个线程成 功地把 sizeCtl 设置为-1,它就拥有了初始化的权利,进入初始化的代码模块,等到初始化完成,再把sizeCtl设置回去;其他线程则一直执行while循环,自旋等待,直到数组不为null,即当初始化结束时, 退出整个方法。
因为初始化的工作量很小,所以此处选择的策略是让其他线程一直等待,而没有帮助其初始化。
3.put(..)实现分析
上面的for循环有4个大的分支: 第1个分支,是整个数组的初始化,前面已讲; 第2个分支,是所在的槽为空,说明该元素是该槽的第一个元素,直接新建一个头节点,然后返回; 第3个分支,说明该槽正在进行扩容,帮助其扩容; 第4个分支,就是把元素放入槽内。槽内可能是一个链表,也可能是一棵红黑树,通过头节点的类型 可以判断是哪一种。第4个分支是包裹在synchronized (f)里面的,f对应的数组下标位置的头节点, 意味着每个数组元素有一把锁,并发度等于数组的长度。
上面的binCount表示链表的元素个数,当这个数目超过TREEIFY_THRESHOLD=8时,把链表转换成 红黑树,也就是 treeifyBin(tab,i)方法。但在这个方法内部,不一定需要进行红黑树转换,可能只做扩容操作,所以接下来从扩容讲起。
4.扩容
扩容的实现是最复杂的,下面从treeifyBin(Node
在上面的代码中,MIN_TREEIFY_CAPACITY=64,意味着当数组的长度没有超过64的时候,数组的 每个节点里都是链表,只会扩容,不会转换成红黑树。只有当数组长度大于或等于64时,才考虑把链表 转换成红黑树。 在 tryPresize(int size)内部调用了一个核心方法 transfer(Node<K,V>[] tab,Node<K,V >[] nextTab),先从这个方法的分析说起。
1private final void transfer(Node
31 32
33
// 以下是哪个分支中的advance都是false,表示如果三个分支都不执行,才可以一
直while循环
// 目的在于当对transferIndex执行CAS操作不成功的时候,需要自旋,以期获取一个stride的迁移任务。
34 if (--i >= bound || finishing)
35 // 对数组遍历,通过这里的--i进行。如果成功执行了--i,就不需要继续
while循环了,因为advance只能进一步。
36 advance = false;
37 else if ((nextIndex = transferIndex) <= 0) {
38 // transferIndex <= 0,整个HashMap完成
39 i = -1;
40 advance = false;
41 }
42 // 对transferIndex执行CAS操作,即为当前线程分配1个stride。
43 // CAS操作成功,线程成功获取到一个stride的迁移任务;
44 // CAS操作不成功,线程没有抢到任务,会继续执行while循环,自旋。
45 else if (U.compareAndSetInt
46 (this, TRANSFERINDEX, nextIndex,
47 nextBound = (nextIndex > stride ?
48 nextIndex - stride : 0))) {
49 bound = nextBound;
50 i = nextIndex - 1;
51 advance = false;
52 }
53 }
54 // i越界,整个HashMap遍历完成
55 if (i < 0 || i >= n || i + n >= nextn) {
56 int sc;
57 // finishing表示整个HashMap扩容完成
58 if (finishing) {
59 nextTable = null;
60 // 将nextTab赋值给当前table
61 table = nextTab;
62 sizeCtl = (n << 1) - (n >>> 1);
63 return;
64 }
65 if (U.compareAndSetInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
66 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
67 return;
68 finishing = advance = true;
69 i = n; // recheck before commit
70 }
71 }
72 // tab[i]迁移完毕,赋值一个ForwardingNode
73 else if ((f = tabAt(tab, i)) == null)
74 advance = casTabAt(tab, i, null, fwd);
75 // tab[i]的位置已经在迁移过程中
76 else if ((fh = f.hash) == MOVED)
77 advance = true; // already processed
78 else {
79 // 对tab[i]进行迁移操作,tab[i]可能是一个链表或者红黑树
80 synchronized (f) {
81 if (tabAt(tab, i) == f) {
82 Node
83 // 链表
84 if (fh >= 0) {
85 int runBit = fh & n;
{
Node
int h = e.hash;
TreeNode
该方法非常复杂,下面一步步分析:
1.扩容的基本原理如下图,首先建一个新的HashMap,其数组长度是旧数组长度的2倍,然后把 旧的元素逐个迁移过来。所以,上面的方法参数有2个,第1个参数tab是扩容之前的HashMap,第2个参数nextTab是扩容之后的HashMap。当nextTab=null的时候,方法最初 会对nextTab进行初始化。这里有一个关键点要说明:该方法会被多个线程调用,所以每个线 程只是扩容旧的HashMap部分,这就涉及如何划分任务的问题。 2.上图为多个线程并行扩容-任务划分示意图。旧数组的长度是N,每个线程扩容一段,一段的长 度用变量stride(步长)来表示,transferIndex表示了整个数组扩容的进度。 stride的计算公式如上面的代码所示,即:在单核模式下直接等于n,因为在单核模式下没有办 法多个线程并行扩容,只需要1个线程来扩容整个数组;在多核模式下为 (n>>> 3)/NCPU,并且保证步长的最小值是 16。显然,需要的线程个数约为n/stride。
transferIndex是ConcurrentHashMap的一个成员变量,记录了扩容的进度。初始值为n,从大到 小扩容,每次减stride个位置,最终减至n<=0,表示整个扩容完成。因此,从[0,transferIndex-1]的 位置表示还没有分配到线程扩容的部分,从[transfexIndex,n-1]的位置表示已经分配给某个线程进行扩 容,当前正在扩容中,或者已经扩容成功。 因为transferIndex会被多个线程并发修改,每次减stride,所以需要通过CAS进行操作,如下面的代码 所示。
3.在扩容未完成之前,有的数组下标对应的槽已经迁移到了新的HashMap里面,有的还在旧的HashMap 里面。这个时候,所有调用 get(k,v)的线程还是会访问旧 HashMap,怎么处理呢? 下图为扩容过程中的转发示意图:当Node[0]已经迁移成功,而其他Node还在迁移过程中时, 如果有线程要读取Node[0]的数据,就会访问失败。为此,新建一个ForwardingNode,即转 发节点,在这个节点里面记录的是新的 ConcurrentHashMap 的引用。这样,当线程访问到ForwardingNode之后,会去查询新的ConcurrentHashMap。 4.因为数组的长度 tab.length 是2的整数次方,每次扩容又是2倍。而 Hash 函数是hashCode%tab.length,等价于hashCode&(tab.length-1)。这意味着:处于第i个位置的 元素,在新的Hash表的数组中一定处于第i个或者第i+n个位置,如下图所示。举个简单的例 子:假设数组长度是8,扩容之后是16: 若hashCode=5,5%8=0,扩容后,5%16=0,位置保持不变;
若hashCode=24,24%8=0,扩容后,24%16=8,后移8个位置; 若hashCode=25,25%8=1,扩容后,25%16=9,后移8个位置; 若hashCode=39,39%8=7,扩容后,39%8=7,位置保持不变; ……
正因为有这样的规律,所以如下有代码:
也就是把tab[i]位置的链表或红黑树重新组装成两部分,一部分链接到nextTab[i]的位置,一部分链 接到nextTab[i+n]的位置,如上图所示。然后把tab[i]的位置指向一个ForwardingNode节点。 同时,当tab[i]后面是链表时,使用类似于JDK 7中在扩容时的优化方法,从lastRun往后的所有节点,不需依次拷贝,而是直接链接到新的链表头部。从lastRun往前的所有节点,需要依次拷贝。 了解了核心的迁移函数transfer(tab,nextTab),再回头看tryPresize(int size)函数。这个函数的输入是整个Hash表的元素个数,在函数里面,根据需要对整个Hash表进行扩容。想要看明白这个 函数,需要透彻地理解sizeCtl变量,下面这段注释摘自源码。
当sizeCtl=-1时,表示整个HashMap正在初始化; 当sizeCtl=某个其他负数时,表示多个线程在对HashMap做并发扩容; 当sizeCtl=cap时,tab=null,表示未初始之前的初始容量(如上面的构造函数所示); 扩容成功之后,sizeCtl存储的是下一次要扩容的阈值,即上面初始化代码中的n-(n>>>2) =0.75n。 所以,sizeCtl变量在Hash表处于不同状态时,表达不同的含义。明白了这个道理,再来看上面的 tryPresize(int size)函数。
tryPresize(int size)是根据期望的元素个数对整个Hash表进行扩容,核心是调用transfer函数。在第一次扩容的时候,sizeCtl会被设置成一个很大的负数U.compareAndSwapInt(this,SIZECTL, sc,(rs << RESIZE_STAMP_SHIFT)+2);之后每一个线程扩容的时候,sizeCtl 就加 1, U.compareAndSwapInt(this,SIZECTL,sc,sc+1),待扩容完成之后,sizeCtl减1。
5.6ConcurrentSkipListMap/Set ConcurrentHashMap 是一种 key 无序的 HashMap,ConcurrentSkipListMap则是 key 有序的, 实现了NavigableMap接口,此接口又继承了SortedMap接口。
5.6.1ConcurrentSkipListMap 1.为什么要使用SkipList实现Map? 在Java的util包中,有一个非线程安全的HashMap,也就是TreeMap,是key有序的,基于红黑树实 现。 而在Concurrent包中,提供的key有序的HashMap,也就是ConcurrentSkipListMap,是基于 SkipList(跳查表)来实现的。这里为什么不用红黑树,而用跳查表来实现呢? 借用Doug Lea的原话:
也就是目前计算机领域还未找到一种高效的、作用在树上的、无锁的、增加和删除节点的办法。 那为什么SkipList可以无锁地实现节点的增加、删除呢?这要从无锁链表的实现说起。
2.无锁链表 在前面讲解AQS时,曾反复用到无锁队列,其实现也是链表。究竟二者的区别在哪呢? 前面讲的无锁队列、栈,都是只在队头、队尾进行CAS操作,通常不会有问题。如果在链表的中间 进行插入或删除操作,按照通常的CAS做法,就会出现问题! 关于这个问题,Doug Lea的论文中有清晰的论述,此处引用如下: 操作1:在节点10后面插入节点20。如下图所示,首先把节点20的next指针指向节点30,然后对节 点10的next指针执行CAS操作,使其指向节点20即可。
操作2:删除节点10。如下图所示,只需把头节点的next指针,进行CAS操作到节点30即可。
但是,如果两个线程同时操作,一个删除节点10,一个要在节点10后面插入节点20。并且这两个操 作都各自是CAS的,此时就会出现问题。如下图所示,删除节点10,会同时把新插入的节点20也删除 掉!这个问题超出了CAS的解决范围。
为什么会出现这个问题呢? 究其原因:在删除节点10的时候,实际受到操作的是节点10的前驱,也就是头节点。节点10本身没 有任何变化。故而,再往节点10后插入节点20的线程,并不知道节点10已经被删除了! 针对这个问题,在论文中提出了如下的解决办法,如下图所示,把节点 10 的删除分为两2步: 第一步,把节点10的next指针,mark成删除,即软删除; 第二步,找机会,物理删除。 做标记之后,当线程再往节点10后面插入节点20的时候,便可以先进行判断,节点10是否已经被删 除,从而避免在一个删除的节点10后面插入节点20。这个解决方法有一个关键点:“把节点10的next指 针指向节点20(插入操作)”和“判断节点10本身是否已经删除(判断操作)”,必须是原子的,必须在1 个CAS操作里面完成!
具体的实现有两个办法: 办法一:AtomicMarkableReference 保证每个 next 是 AtomicMarkableReference 类型。但这个办法不够高效,Doug Lea 在 ConcurrentSkipListMap的实现中用了另一种办法。 办法2:Mark节点 我们的目的是标记节点10已经删除,也就是标记它的next字段。那么可以新造一个marker节点,使 节点10的next指针指向该Marker节点。这样,当向节点10的后面插入节点20的时候,就可以在插入的 同时判断节点10的next指针是否指向了一个Marker节点,这两个操作可以在一个CAS操作里面完成。
3.跳查表 解决了无锁链表的插入或删除问题,也就解决了跳查表的一个关键问题。因为跳查表就是多层链表 叠起来的。 下面先看一下跳查表的数据结构(下面所用代码都引用自JDK 7,JDK 8中的代码略有差异,但不影响下面的原理分析)。
上图中的Node就是跳查表底层节点类型。所有的
上图中的node属性不存储实际数据,指向Node节点。 down属性:每个Index节点,必须有一个指针,指向其下一个Level对应的节点。
right属性:Index也组成单向链表。
整个ConcurrentSkipListMap就只需要记录顶层的head节点即可:
下面详细分析如何从跳查表上查找、插入和删除元素。 1.put实现分析
while ((r = q.right) != null) { Node
else
}
break;
if ((d = q.down) != null) { ++levels; q = d; } else { b = q.node; break; }
35 }
36if (b != null) {
37Node
在底层,节点按照从小到大的顺序排列,上面的index层间隔地串在一起,因为从小到大排列。查找 的时候,从顶层index开始,自左往右、自上往下,形成图示的遍历曲线。假设要查找的元素是32,遍 历过程如下: 先遍历第2层Index,发现在21的后面; 从21下降到第1层Index,从21往后遍历,发现在21和35之间; 从21下降到底层,从21往后遍历,最终发现在29和35之间。
在整个的查找过程中,范围不断缩小,最终定位到底层的两个元素之间。
关于上面的put(...)方法,有一个关键点需要说明:在通过findPredecessor找到了待插入的元素在[b,n]之间之后,并不能马上插入。因为其他线程也在操作这个链表,b、n都有可能被删除,所以在插 入之前执行了一系列的检查逻辑,而这也正是无锁链表的复杂之处。
2.remove(...)分析
上面的删除方法和插入方法的逻辑非常类似,因为无论是插入,还是删除,都要先找到元素的前 驱,也就是定位到元素所在的区间[b,n]。在定位之后,执行下面几个步骤: 1.如果发现b、n已经被删除了,则执行对应的删除清理逻辑; 2.否则,如果没有找到待删除的(k, v),返回null; 3.如果找到了待删除的元素,也就是节点n,则把n的value置为null,同时在n的后面加上 Marker节点,同时检查是否需要降低Index的层次。
- get分析
1private V doGet(Object key) {
2Index
无论是插入、删除,还是查找,都有相似的逻辑,都需要先定位到元素位置[b,n],然后判断b、n 是否已经被删除,如果是,则需要执行相应的删除清理逻辑。这也正是无锁链表复杂的地方。
5.6.2ConcurrentSkipListSet 如下面代码所示,ConcurrentSkipListSet只是对ConcurrentSkipListMap的简单封装,此处不再进 一步展开叙述。
6. 同步工具类
6.1 Semaphore
Semaphore也就是信号量,提供了资源数量的并发访问控制,其使用代码很简单,如下所示:
案例: 大学生到自习室抢座,写作业:
如下图所示,假设有n个线程来获取Semaphore里面的10份资源(n > 10),n个线程中只有10个线程能获取到,其他线程都会阻塞。直到有线程释放了资源,其他线程才能获取到。
当初始的资源个数为1的时候,Semaphore退化为排他锁。正因为如此,Semaphone的实现原理和 锁十分类似,是基于AQS,有公平和非公平之分。Semaphore相关类的继承体系如下图所示:
由于Semaphore和锁的实现原理基本相同,上面的代码不再展开解释。资源总数即state的初始 值,在acquire里对state变量进行CAS减操作,减到0之后,线程阻塞;在release里对state变量进行CAS加操作。
6.2 CountDownLatch
6.2.1CountDownLatch使用场景 假设一个主线程要等待5个 Worker 线程执行完才能退出,可以使用CountDownLatch来实现: 线程:
Main类:
15
16 // 当前线程等待
17 latch.await();
18 System.out.println("程序运行结束");
19 }
20 }
下图为CountDownLatch相关类的继承层次,CountDownLatch原理和Semaphore原理类似,同样 是基于AQS,不过没有公平和非公平之分。
6.2.2await()实现分析 如下所示,await()调用的是AQS 的模板方法,这个方法在前面已经介绍过。 CountDownLatch.Sync重新实现了tryAccuqireShared方法:
从tryAcquireShared(...)方法的实现来看,只要state != 0,调用await()方法的线程便会被放入AQS 的阻塞队列,进入阻塞状态。
6.2.3countDown()实现分析
countDown()调用的AQS的模板方法releaseShared(),里面的tryReleaseShared(...)由CountDownLatch.Sync实现。从上面的代码可以看出,只有state=0,tryReleaseShared(...)才会返回true,然后执行doReleaseShared(...),一次性唤醒队列中所有阻塞的线程。 总结:由于是基于AQS阻塞队列来实现的,所以可以让多个线程都阻塞在state=0条件上,通过countDown()一直减state,减到0后一次性唤醒所有线程。如下图所示,假设初始总数为M,N个线程await(),M个线程countDown(),减到0之后,N个线程被唤醒。
6.3 CyclicBarrier
6.3.1CyclicBarrier使用场景 CyclicBarrier使用方式比较简单:
该类用于协调多个线程同步执行操作的场合。
使用场景:10个工程师一起来公司应聘,招聘方式分为笔试和面试。首先,要等人到齐后,开始笔 试;笔试结束之后,再一起参加面试。把10个人看作10个线程,10个线程之间的同步过程如下图所示:
Main类:
8 CyclicBarrier barrier = new CyclicBarrier(5);
9
10 for (int i = 0; i < 5; i++) {
11 new MyThread("线程-" + (i + 1), barrier).start();
12 }
13
14 }
15 }
MyThread类:
在整个过程中,有2个同步点:第1个同步点,要等所有应聘者都到达公司,再一起开始笔试;第2 个同步点,要等所有应聘者都结束笔试,之后一起进入面试环节。
6.3.2CyclicBarrier实现原理 CyclicBarrier基于ReentrantLock+Condition实现。
下面详细介绍 CyclicBarrier 的实现原理。先看构造方法:
接下来看一下await()方法的实现过程。
1public int await() throws InterruptedException, BrokenBarrierException { 2try { 3return dowait(false, 0L); 4} catch (TimeoutException toe) { 5throw new Error(toe); // cannot happen 6 } 7 } 8 9 private int dowait(boolean timed, long nanos) 10throws InterruptedException, BrokenBarrierException, 11TimeoutException { 12final ReentrantLock lock = this.lock; 13lock.lock(); 14try { 15final Generation g = generation; 16 17if (g.broken) 18throw new BrokenBarrierException(); 19// 响应中断 20if (Thread.interrupted()) { 21// 唤醒所有阻塞的线程 22breakBarrier(); 23throw new InterruptedException(); 24 } 25 26// 每个线程调用一次await(),count都要减1 27int index = --count; 28// 当count减到0的时候,此线程唤醒其他所有线程 29if (index == 0) { // tripped 30boolean ranAction = false; 31try { 32final Runnable command = barrierCommand; 33if (command != null) 34command.run(); 35ranAction = true; 36nextGeneration(); 37return 0; 38} finally { 39if (!ranAction) 40breakBarrier(); 41 } 42 } 43 44 // loop until tripped, broken, interrupted, or timed out
45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 } 78
for (;;) { try { if (!timed) trip.await(); else if (nanos > 0L) nanos = trip.awaitNanos(nanos); } catch (InterruptedException ie) { if (g == generation && ! g.broken) { breakBarrier(); throw ie; } else { // We're about to finish waiting even if we had not // been interrupted, so this interrupt is deemed to // "belong" to subsequent execution. Thread.currentThread().interrupt(); } }
if (g.broken) throw new BrokenBarrierException();
if (g != generation) return index;
if (timed && nanos <= 0L) { breakBarrier(); throw new TimeoutException(); } } } finally { lock.unlock(); }
79private void breakBarrier() { 80generation.broken = true; 81count = parties; 82trip.signalAll(); 83 } 84 85private void nextGeneration() { 86// signal completion of last generation 87trip.signalAll(); 88// set up next generation 89count = parties; 90generation = new Generation(); 91 }
关于上面的方法,有几点说明: 1.CyclicBarrier是可以被重用的。以上一节的应聘场景为例,来了10个线程,这10个线程互相等 待,到齐后一起被唤醒,各自执行接下来的逻辑;然后,这10个线程继续互相等待,到齐后再 一起被唤醒。每一轮被称为一个Generation,就是一次同步点。 2.CyclicBarrier 会响应中断。10 个线程没有到齐,如果有线程收到了中断信号,所有阻塞的线程也会被唤醒,就是上面的breakBarrier()方法。然后count被重置为初始值(parties),重
新开始。 3.上面的回调方法,barrierAction只会被第10个线程执行1次(在唤醒其他9个线程之前),而 不是10个线程每个都执行1次。
6.4 Exchanger
6.4.1使用场景 Exchanger用于线程之间交换数据,其使用代码很简单,是一个exchange(...)方法,使用示例如 下:
1 package com.lagou.concurrent.demo; 2
3import java.util.Random;
4import java.util.concurrent.Exchanger; 5
6public class Main {
7private static final Random random = new Random();
8public static void main(String[] args) {
9// 建一个多线程共用的exchange对象
10 // 把exchange对象传给3个线程对象。每个线程在自己的run方法中调用exchange,把自己的数据作为参数
11// 传递进去,返回值是另外一个线程调用exchange传进去的参数
12Exchanger
- "得到<==" + otherData); 22Thread.sleep(random.nextInt(2000)); 23} catch (InterruptedException e) { 24e.printStackTrace(); 25 } 26 } 27 } 28 }.start(); 29 30new Thread("线程2") { 31@Override 32public void run() { 33while (true) { 34try { 35String otherData = exchanger.exchange("交换数据2"); 36System.out.println(Thread.currentThread().getName()
- "得到<==" + otherData); 37Thread.sleep(random.nextInt(2000)); 38} catch (InterruptedException e) { 39e.printStackTrace();
在上面的例子中,3个线程并发地调用exchange(...),会两两交互数据,如1/2、1/3和2/3。
6.4.2实现原理 Exchanger的核心机制和Lock一样,也是CAS+park/unpark。 首先,在Exchanger内部,有两个内部类:Participant和Node,代码如下:
每个线程在调用exchange(...)方法交换数据的时候,会先创建一个Node对象。
这个Node对象就是对该线程的包装,里面包含了3个重要字段:第一个是该线程要交互的数据,第 二个是对方线程交换来的数据,最后一个是该线程自身。 一个Node只能支持2个线程之间交换数据,要实现多个线程并行地交换数据,需要多个Node,因 此在Exchanger里面定义了Node数组:
6.4.3exchange(V x)实现分析 明白了大致思路,下面来看exchange(V x)方法的详细实现:
上面方法中,如果arena不是null,表示启用了arena方式交换数据。如果arena不是null,并且线程 被中断,则抛异常 如果arena不是null,并且arenaExchange的返回值为null,则抛异常。对方线程交换来的null值是 封装为NULL_ITEM对象的,而不是null。 如果slotExchange的返回值是null,并且线程被中断,则抛异常。 如果slotExchange的返回值是null,并且areaExchange的返回值是null,则抛异常。
slotExchange的实现:
13private final Object slotExchange(Object item, boolean timed, long ns) { 14// participant在初始化的时候设置初始值为new Node() 15// 获取本线程要交换的数据节点 16Node p = participant.get(); 17// 获取当前线程 18Thread t = Thread.currentThread(); 19// 如果线程被中断,则返回null。 20if (t.isInterrupted()) 21return null; 22 23for (Node q;;) { 24// 如果slot非空,表明有其他线程在等待该线程交换数据 25if ((q = slot) != null) { 26// CAS操作,将当前线程的slot由slot设置为null 27// 如果操作成功,则执行if中的语句 28if (SLOT.compareAndSet(this, q, null)) { 29// 获取对方线程交换来的数据 30Object v = q.item; 31// 设置要交换的数据 32q.match = item; 33// 获取q中阻塞的线程对象 34Thread w = q.parked; 35if (w != null) 36// 如果对方阻塞的线程非空,则唤醒阻塞的线程 37LockSupport.unpark(w); 38return v; 39 } 40// create arena on contention, but continue until slot null 41// 创建arena用于处理多个线程需要交换数据的场合,防止slot冲突 42if (NCPU > 1 && bound == 0 && 43BOUND.compareAndSet(this, 0, SEQ)) { 44arena = new Node[(FULL + 2) << ASHIFT]; 45 } 46 } 47 // 如果arena不是null,需要调用者调用arenaExchange方法接着获取对方线程交
换来的数据 48 49 50 51 52 53 54 55 56 57 58 59 60 } 61
else if (arena != null) return null; else { // 如果slot为null,表示对方没有线程等待该线程交换数据 // 设置要交换的本方数据 p.item = item; // 设置当前线程要交换的数据到slot // CAS操作,如果设置失败,则进入下一轮for循环if (SLOT.compareAndSet(this, null, p)) break; p.item = null; }
62// 没有对方线程等待交换数据,将当前线程要交换的数据放到slot中,是一个Node对象 63// 然后阻塞,等待唤醒 64int h = p.hash; 65// 如果是计时等待交换,则计算超时时间;否则设置为0。 66long end = timed ? System.nanoTime() + ns : 0L; 67// 如果CPU核心数大于1,则使用SPINS数,自旋;否则为1,没必要自旋。 68int spins = (NCPU > 1) ? SPINS : 1;
69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100
101 102 103 104 105 106 107 108 109 110
null;
}
// 记录对方线程交换来的数据 Object v; // 如果p.match==null,表示还没有线程交换来数据 while ((v = p.match) == null) { // 如果自旋次数大于0,计算hash随机数 if (spins > 0) { // 生成随机数,用于自旋次数控制 h ^= h << 1; h ^= h >>> 3; h ^= h << 10; if (h == 0) h = SPINS | (int)t.getId(); else if (h < 0 && (--spins & ((SPINS >>> 1) - 1)) == 0) Thread.yield(); // p是ThreadLocal记录的当前线程的Node。 // 如果slot不是p表示slot是别的线程放进去的 } else if (slot != p) { spins = SPINS; } else if (!t.isInterrupted() && arena == null && (!timed || (ns = end - System.nanoTime()) > 0L)) { p.parked = t; if (slot == p) { if (ns == 0L) // 阻塞当前线程 LockSupport.park(this); else // 如果是计时等待,则阻塞当前线程指定时间 LockSupport.parkNanos(this, ns); } p.parked = null; } else if (SLOT.compareAndSet(this, p, null)) { // 没有被中断但是超时了,返回TIMED_OUT,否则返回null v = timed && ns <= 0L && !t.isInterrupted() ? TIMED_OUT :
break; } } // match设置为null值 CAS MATCH.setRelease(p, null); p.item = null; p.hash = h; // 返回获取的对方线程交换来的数据 return v;
111 112 }
// ...
arenaExchange的实现:
8
9
10
11 @param item 本线程要交换的非null数据。
@param timed 如果需要计时等待,则设置为true。
@param ns 表示计时等待的最大时长。
@return 对方线程交换来的数据。如果线程被中断,或者等待超时,则返回null。
12 */
13 private final Object arenaExchange(Object item, boolean timed, long ns)
{
14 Node[] a = arena;
15 int alen = a.length;
16 Node p = participant.get();
17 // 访问下标为i处的slot数据
18 for (int i = p.index;;) { // access slot at i
19 int b, m, c;
20 int j = (i << ASHIFT) + ((1 << ASHIFT) - 1);
21 if (j < 0 || j >= alen)
22 j = alen - 1;
23
24 // 取出arena数组的第j个Node元素
25 Node q = (Node)AA.getAcquire(a, j);
26 // 如果q不是null,则将数组的第j个元素由q设置为null
27 if (q != null && AA.compareAndSet(a, j, q, null)) {
28 // 获取对方线程交换来的数据
29 Object v = q.item; // release
30 // 设置本方线程交换的数据
31 q.match = item;
32 // 获取对方线程对象
33 Thread w = q.parked;
34 if (w != null)
35 // 如果对方线程非空,则唤醒对方线程
36 LockSupport.unpark(w);
37 return v;
38 }
39 // 如果自旋次数没达到边界,且q为null
40 else if (i <= (m = (b = bound) & MMASK) && q == null) {
41 // 提供本方数据
42 p.item = item; // offer
43 // 将arena的第j个元素由null设置为p
44 if (AA.compareAndSet(a, j, null, p)) {
45 long end = (timed && m == 0) ? System.nanoTime() + ns :
0L;
46 Thread t = Thread.currentThread(); // wait
47 // 自旋等待
48 for (int h = p.hash, spins = SPINS;;) {
49 // 获取对方交换来的数据
50 Object v = p.match;
51 // 如果对方交换来的数据非空
52 if (v != null) {
53 // 将p设置为null,CAS操作
54 MATCH.setRelease(p, null);
55 // 清空
56 p.item = null; // clear for next
use
57 p.hash = h;
58 // 返回交换来的数据
59 return v;
60 }
61 // 产生随机数,用于限制自旋次数
62 else if (spins > 0) {
63
64 65 66 67 68
69 70 71 72
73 74 75 76 77 78 79 80 81 82 83 84 85 86
87
88
89
90
91
92
93
94
95
96
97
98
99 h ^= h << 1; h ^= h >>> 3; h ^= h << 10; //
xorshift
if (h == 0) // initialize hash h = SPINS | (int)t.getId();
else if (h < 0 && // approx 50% true (--spins & ((SPINS >>> 1) - 1)) == 0)
Thread.yield(); // two yields per
wait
}
// 如果arena的第j个元素不是p
else if (AA.getAcquire(a, j) != p)
spins = SPINS; // releaser hasn't set
match yet
else if (!t.isInterrupted() && m == 0 && (!timed ||
(ns = end - System.nanoTime()) > 0L)) { p.parked = t; // minimize window if (AA.getAcquire(a, j) == p) {
if (ns == 0L)
// 当前线程阻塞,等待交换数据
LockSupport.park(this);
else
LockSupport.parkNanos(this, ns);
}
p.parked = null;
}
// arena的第j个元素是p并且CAS设置arena的第j个元素由p设置
为null成功
else if (AA.getAcquire(a, j) == p && AA.compareAndSet(a, j, p, null)) {
if (m != 0) // try to shrink BOUND.compareAndSet(this, b, b + SEQ - 1);
p.item = null; p.hash = h;
i = p.index >>>= 1; // descend
// 如果线程被中断,则返回null值
if (Thread.interrupted()) return null;
if (timed && m == 0 && ns <= 0L)
// 如果超时,返回TIMED_OUT。
return TIMED_OUT;
100 break; // expired; restart
101 }
102 }
103 }
104 else
105 p.item = null; // clear offer
106 }
107 //
108 else {
109 if (p.bound != b) { // stale; reset
110 p.bound = b;
111 p.collides = 0;
112
113
114
115
116 i = (i != m || m == 0) ? m : m - 1;
}
else if ((c = p.collides) < m || m == FULL ||
!BOUND.compareAndSet(this, b, b + SEQ + 1)) { p.collides = c + 1;
6.5 Phaser
6.5.1用Phaser替代CyclicBarrier和CountDownLatch 从JDK7开始,新增了一个同步工具类Phaser,其功能比CyclicBarrier和CountDownLatch更加强 大。
1.用Phaser替代CountDownLatch 考虑讲CountDownLatch时的例子,1个主线程要等10个worker线程完成之后,才能做接下来的事 情,也可以用Phaser来实现此功能。在CountDownLatch中,主要是2个方法:await()和 countDown(),在Phaser中,与之相对应的方法是awaitAdance(int n)和arrive()。
2.用Phaser替代CyclicBarrier
考虑前面讲CyclicBarrier时,10个工程师去公司应聘的例子,也可以用Phaser实现,代码基本类 似。
1 package com.lagou.concurrent.demo; 2 3 import java.util.concurrent.Phaser; 4 5public class Main { 6public static void main(String[] args) { 7Phaser phaser = new Phaser(5); 8 9 for (int i = 0; i < 5; i++) { 10 new MyThread("线程-" + (i + 1), phaser).start(); 11 } 12 13 phaser.awaitAdvance(0); 14 15 } 16 } 17 18 package com.lagou.concurrent.demo; 19 20import java.util.Random; 21import java.util.concurrent.Phaser; 22 23 public class MyThread extends Thread { 24 25private final Phaser phaser; 26private final Random random = new Random(); 27 28public MyThread(String name, Phaser phaser) { 29super(name); 30this.phaser = phaser; 31 } 32 33@Override 34public void run() { 35System.out.println(getName() + " - 开始向公司出发"); 36slowly(); 37System.out.println(getName() + " - 已经到达公司"); 38// 到达同步点,等待其他线程 39phaser.arriveAndAwaitAdvance(); 40 41System.out.println(getName() + " - 开始笔试"); 42slowly(); 43System.out.println(getName() + " - 笔试结束"); 44// 到达同步点,等待其他线程 45phaser.arriveAndAwaitAdvance();
arriveAndAwaitAdance()就是 arrive()与 awaitAdvance(int)的组合,表示“我自己已到达这个同步点,同时要等待所有人都到达这个同步点,然后再一起前行”。
6.5.2Phaser新特性 特性1:动态调整线程个数
CyclicBarrier 所要同步的线程个数是在构造方法中指定的,之后不能更改,而 Phaser 可以在运行期间动态地调整要同步的线程个数。Phaser 提供了下面这些方法来增加、减少所要同步的线程个数。
特性2:层次Phaser 多个Phaser可以组成如下图所示的树状结构,可以通过在构造方法中传入父Phaser来实现。
先简单看一下Phaser内部关于树状结构的存储,如下所示:
可以发现,在Phaser的内部结构中,每个Phaser记录了自己的父节点,但并没有记录自己的子节点 列表。所以,每个 Phaser 知道自己的父节点是谁,但父节点并不知道自己有多少个子节点,对父节点的操作,是通过子节点来实现的。
树状的Phaser怎么使用呢?考虑如下代码,会组成下图的树状Phaser。
本来root有两个参与者,然后为其加入了两个子Phaser(c1,c2),每个子Phaser会算作1个参与 者,root的参与者就变成2+2=4个。c1本来有3个参与者,为其加入了一个子Phaser c3,参与者数量变成3+1=4个。c3的参与者初始为0,后续可以通过调用register()方法加入。
对于树状Phaser上的每个节点来说,可以当作一个独立的Phaser来看待,其运作机制和一个单独的 Phaser是一样的。 父Phaser并不用感知子Phaser的存在,当子Phaser中注册的参与者数量大于0时,会把自己向父节 点注册;当子Phaser中注册的参与者数量等于0时,会自动向父节点解除注册。父Phaser把子Phaser当 作一个正常参与的线程就即可。
6.5.3state变量解析 大致了解了Phaser的用法和新特性之后,下面仔细剖析其实现原理。Phaser没有基于AQS来实现, 但具备AQS的核心特性:state变量、CAS操作、阻塞队列。先从state变量说起。
这个64位的state变量被拆成4部分,下图为state变量各部分:
最高位0表示未同步完成,1表示同步完成,初始最高位为0。
Phaser提供了一系列的成员方法来从state中获取上图中的几个数字,如下所示:
下面再看一下state变量在构造方法中是如何被赋值的:
当parties=0时,state被赋予一个EMPTY常量,常量为1; 当parties != 0时,把phase值左移32位;把parties左移16位;然后parties也作为最低的16位,3个值做或操作,赋值给state。
6.5.4阻塞与唤醒(Treiber Stack) 基于上述的state变量,对其执行CAS操作,并进行相应的阻塞与唤醒。如下图所示,右边的主线程 会调用awaitAdvance()进行阻塞;左边的arrive()会对state进行CAS的累减操作,当未到达的线程数减到 0时,唤醒右边阻塞的主线程。
在这里,阻塞使用的是一个称为Treiber Stack的数据结构,而不是AQS的双向链表。Treiber Stack 是一个无锁的栈,它是一个单向链表,出栈、入栈都在链表头部,所以只需要一个head指针,而不需要tail指针,如下的实现:
为了减少并发冲突,这里定义了2个链表,也就是2个Treiber Stack。当phase为奇数轮的时候,阻塞线程放在oddQ里面;当phase为偶数轮的时候,阻塞线程放在evenQ里面。代码如下所示。
6.5.5arrive()方法分析 下面看arrive()方法是如何对state变量进行操作,又是如何唤醒线程的。
arrive()和 arriveAndDeregister()内部调用的都是 doArrive(boolean)方法。 区别在于前者只是把“未达到线程数”减1;后者则把“未到达线程数”和“下一轮的总线程数”都减1。下 面看一下doArrive(boolean)方法的实现。
40 }
41 return phase;
42 }
43 }
44 }
关于上面的方法,有以下几点说明: 1.定义了2个常量如下。 当 deregister=false 时,只最低的16位需要减 1,adj=ONE_ARRIVAL;当deregister=true 时,低32位中的2个16位都需要减1,adj=ONE_ARRIVAL|ONE_PARTY。 2.把未到达线程数减1。减了之后,如果还未到0,什么都不做,直接返回。如果到0,会做2件事 情:第1,重置state,把state的未到达线程个数重置到总的注册的线程数中,同时phase加 1;第2,唤醒队列中的线程。
下面看一下唤醒方法:
遍历整个栈,只要栈当中节点的phase不等于当前Phaser的phase,说明该节点不是当前轮的,而 是前一轮的,应该被释放并唤醒。
6.5.6awaitAdvance()方法分析
下面的while循环中有4个分支: 初始的时候,node==null,进入第1个分支进行自旋,自旋次数满足之后,会新建一个QNode节 点; 之后执行第3、第4个分支,分别把该节点入栈并阻塞。
这里调用了ForkJoinPool.managedBlock(ManagedBlocker blocker)方法,目的是把node对应的线程阻塞。ManagerdBlocker是ForkJoinPool里面的一个接口,定义如下:
QNode实现了该接口,实现原理还是park(),如下所示。之所以没有直接使用park()/unpark()来实 现阻塞、唤醒,而是封装了ManagedBlocker这一层,主要是出于使用上的方便考虑。一方面是park()可 能被中断唤醒,另一方面是带超时时间的park(),把这二者都封装在一起。
1static final class QNode implements ForkJoinPool.ManagedBlocker { 2final Phaser phaser; 3final int phase; 4final boolean interruptible; 5final boolean timed; 6boolean wasInterrupted; 7long nanos; 8final long deadline; 9volatile Thread thread; // nulled to cancel wait 10QNode next; 11QNode(Phaser phaser, int phase, boolean interruptible, 12boolean timed, long nanos) { 13this.phaser = phaser; 14this.phase = phase; 15this.interruptible = interruptible; 16this.nanos = nanos; 17this.timed = timed; 18this.deadline = timed ? System.nanoTime() + nanos : 0L; 19thread = Thread.currentThread(); 20 } 21public boolean isReleasable() { 22if (thread == null) 23return true; 24if (phaser.getPhase() != phase) { 25thread = null; 26return true; 27 } 28if (Thread.interrupted()) 29wasInterrupted = true; 30if (wasInterrupted && interruptible) { 31thread = null; 32return true; 33 } 34if (timed && 35(nanos <= 0L || (nanos = deadline - System.nanoTime()) <= 0L)) { 36thread = null; 37return true; 38 } 39 return false; 40 } 41public boolean block() { 42while (!isReleasable()) { 43if (timed) 44LockSupport.parkNanos(this, nanos); 45else 46LockSupport.park(this); 47 } 48 return true; 49 } 50 }
理解了arrive()和awaitAdvance(),arriveAndAwaitAdvance()就是二者的一个组合版本。
7. Atomic类
7.1 AtomicInteger和AtomicLong
如下面代码所示,对于一个整数的加减操作,要保证线程安全,需要加锁,也就是加synchronized 关键字。
但有了Concurrent包的Atomic相关的类之后,synchronized关键字可以用AtomicInteger代替,其 性能更好,对应的代码变为:
其对应的源码如下:
上图中的U是Unsafe的对象:
AtomicInteger的getAndIncrement() 方法和getAndDecrement() 方法都调用了一个方法: U.getAndAddInt(…) 方法,该方法基于CAS实现:
do-while循环直到判断条件返回true为止。该操作称为自旋。
getAndAddInt 方法具有volatile的语义,也就是对所有线程都是同时可见的。而weakCompareAndSetInt 方法的实现:
调用了compareAndSetInt 方法,该方法的实现:
上图中的方法中, 第一个参数表示要修改哪个对象的属性值; 第二个参数是该对象属性在内存的偏移量; 第三个参数表示期望值; 第四个参数表示要设置为的目标值。
源码比较简单,重要的是其中的设计思想。
7.1.1悲观锁与乐观锁 对于悲观锁,认为数据发生并发冲突的概率很大,读操作之前就上锁。synchronized关键字,后面 要讲的ReentrantLock都是悲观锁的典型。
对于乐观锁,认为数据发生并发冲突的概率比较小,读操作之前不上锁。等到写操作的时候,再判 断数据在此期间是否被其他线程修改了。如果被其他线程修改了,就把数据重新读出来,重复该过程; 如果没有被修改,就写回去。判断数据是否被修改,同时写回新值,这两个操作要合成一个原子操作, 也就是CAS ( Compare And Set )。
AtomicInteger的实现就是典型的乐观锁。
7.1.2Unsafe 的CAS详解 Unsafe类是整个Concurrent包的基础,里面所有方法都是native的。具体到上面提到的compareAndSetInt方法,即:
要特别说明一下第二个参数,它是一个long型的整数,经常被称为xxxOffset,意思是某个成员变量 在对应的类中的内存偏移量(该变量在内存中的位置),表示该成员变量本身。 第二个参数的值为AtomicInteger中的属性VALUE:
VALUE的值:
而Unsafe的 objectFieldOffset(...) 方法调用,就是为了找到AtomicInteger类中value属性所在的内存偏移量。 objectFieldOffset 方法的实现:
其中objectFieldOffset1的实现为:
所有调用CAS的地方,都会先通过这个方法把成员变量转换成一个Offset。以AtomicInteger为例:
从上面代码可以看到,无论是Unsafe还是VALUE,都是静态的,也就是类级别的,所有对象共用 的。 此处的VALUE就代表了value变量本身,后面执行CAS操作的时候,不是直接操作value,而是操作 VALUE。
7.1.3自旋与阻塞 当一个线程拿不到锁的时候,有以下两种基本的等待策略: 策略1:放弃CPU,进入阻塞状态,等待后续被唤醒,再重新被操作系统调度。 策略2:不放弃CPU,空转,不断重试,也就是所谓的“自旋”。
很显然,如果是单核的CPU,只能用策略1。因为如果不放弃CPU,那么其他线程无法运行,也就无 法释放锁。但对于多CPU或者多核,策略2就很有用了,因为没有线程切换的开销。
AtomicInteger的实现就用的是“自旋”策略,如果拿不到锁,就会一直重试。
注意:以上两种策略并不互斥,可以结合使用。如果获取不到锁,先自旋;如果自旋还拿不到锁, 再阻塞,synchronized关键字就是这样的实现策略。 除了AtomicInteger,AtomicLong也是同样的原理。
7.2 AtomicBoolean和AtomicReference
7.2.1为什么需要AtomicBoolean 对于int或者long型变量,需要进行加减操作,所以要加锁;但对于一个boolean类型来说,true或 false的赋值和取值操作,加上volatile关键字就够了,为什么还需要AtomicBoolean呢?
这是因为往往要实现下面这种功能:
也就是要实现 compare和set两个操作合在一起的原子性,而这也正是CAS提供的功能。上面的代码,就变成:
同样地,AtomicReference也需要同样的功能,对应的方法如下:
其中,expect是旧的引用,update为新的引用。
7.2.2如何支持boolean和double类型 在Unsafe类中,只提供了三种类型的CAS操作:int、long、Object(也就是引用类型)。如下所 示:
即,在jdk的实现中,这三种CAS操作都是由底层实现的,其他类型的CAS操作都要转换为这三种之 一进行操作。
其中的参数: 1.第一个参数是要修改的对象 2.第二个参数是对象的成员变量在内存中的位置(一个long型的整数) 3.第三个参数是该变量的旧值 4.第四个参数是该变量的新值。
AtomicBoolean类型如何支持? 对于用int型来代替的,在入参的时候,将boolean类型转换成int类型;在返回值的时候,将int类型 转换成boolean类型。如下所示:
如果是double类型,又如何支持呢? 这依赖double类型提供的一对double类型和long类型互转的方法:
Unsafe类中的方法实现:
7.3 AtomicStampedReference和AtomicMarkableReference
7.3.1ABA问题与解决办法 到目前为止,CAS都是基于“值”来做比较的。但如果另外一个线程把变量的值从A改为B,再从B改回 到A,那么尽管修改过两次,可是在当前线程做CAS操作的时候,却会因为值没变而认为数据没有被其他 线程修改过,这就是所谓的ABA问题。 举例来说: 小张欠小李100块,约定今天还,给打到网银。 小李家的网银余额是0,打过来之后应该是100块。 小张今天还钱这个事小李知道,小李还告诉了自己媳妇。小张还钱,小李媳妇看到了,就取出来花掉了。 小李恰好在他媳妇取出之后检查账户,一看余额还是0。 然后找小张,要账。
这其中,小李家的账户余额从0到100,再从100到0,小李一开始检查是0,第二次检查还是0,就 认为小张没还钱。 实际上小李媳妇花掉了。 ABA问题。 其实小李可以查看账户的收支记录。
要解决 ABA 问题,不仅要比较“值”,还要比较“版本号”,而这正是 AtomicStampedReference做的事情,其对应的CAS方法如下:
之前的 CAS只有两个参数,这里的 CAS有四个参数,后两个参数就是版本号的旧值和新值。当expectedReference != 对象当前的reference时,说明该数据肯定被其他线程修改过; 当expectedReference == 对象当前的reference时,再进一步比较expectedStamp是否等于对象当前的版本号,以此判断数据是否被其他线程修改过。
7.3.2为什么没有AtomicStampedInteger或AtomictStampedLong 要解决Integer或者Long型变量的ABA问题,为什么只有AtomicStampedReference,而没有 AtomicStampedInteger或者AtomictStampedLong呢?
因为这里要同时比较数据的“值”和“版本号”,而Integer型或者Long型的CAS没有办法同时比较两个 变量。 于是只能把值和版本号封装成一个对象,也就是这里面的Pair内部类,然后通过对象引用的CAS来 实现。代码如下所示:
当使用的时候,在构造方法里面传入值和版本号两个参数,应用程序对版本号进行累加操作,然后 调用上面的CAS。如下所示:
7.3.3AtomicMarkableReference AtomicMarkableReference与AtomicStampedReference原理类似,只是Pair里面的版本号是boolean类型的,而不是整型的累加变量,如下所示:
因为是boolean类型,只能有true、false 两个版本号,所以并不能完全避免ABA问题,只是降低了 ABA发生的概率。
7.4 AtomicIntegerFieldUpdater、AtomicLongFieldUpdater和AtomicReferenceFieldUpdater
7.4.1为什么需要AtomicXXXFieldUpdater 如果一个类是自己编写的,则可以在编写的时候把成员变量定义为Atomic类型。但如果是一个已经 有的类,在不能更改其源代码的情况下,要想实现对其成员变量的原子操作,就需要AtomicIntegerFieldUpdater、AtomicLongFieldUpdater 和 AtomicReferenceFieldUpdater。 通过AtomicIntegerFieldUpdater理解它们的实现原理。 AtomicIntegerFieldUpdater是一个抽象类。 首先,其构造方法是protected,不能直接构造其对象,必须通过它提供的一个静态方法来创建,如 下所示: 方法newUpdater 用于创建AtomicIntegerFieldUpdater类对象:
newUpdater(...)静态方法传入的是要修改的类(不是对象)和对应的成员变量的名字,内部通过反 射拿到这个类的成员变量,然后包装成一个AtomicIntegerFieldUpdater对象。所以,这个对象表示的是 类的某个成员,而不是对象的成员变量。
若要修改某个对象的成员变量的值,再传入相应的对象,如下所示:
accecssCheck方法的作用是检查该obj是不是tclass类型,如果不是,则拒绝修改,抛出异常。 从代码可以看到,其 CAS 原理和 AtomictInteger 是一样的,底层都调用了 Unsafe 的 compareAndSetInt(...)方法。
7.4.2限制条件 要想使用AtomicIntegerFieldUpdater修改成员变量,成员变量必须是volatile的int类型(不能是 Integer包装类),该限制从其构造方法中可以看到:
至于 AtomicLongFieldUpdater、AtomicReferenceFieldUpdater,也有类似的限制条件。其底层的CAS原理,也和AtomicLong、AtomicReference一样。
7.5 AtomicIntegerArray、AtomicLongArray和AtomicReferenceArray
Concurrent包提供了AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray三个数组 元素的原子操作。注意,这里并不是说对整个数组的操作是原子的,而是针对数组中一个元素的原子操 作而言。
7.5.1使用方式 以AtomicIntegerArray为例,其使用方式如下:
相比于AtomicInteger的getAndIncrement()方法,这里只是多了一个传入参数:数组的下标i。 其他方法也与此类似,相比于 AtomicInteger 的各种加减方法,也都是多一个下标 i,如下所示。
7.5.2实现原理 其底层的CAS方法直接调用VarHandle中native的getAndAdd方法。如下所示:
明白了AtomicIntegerArray的实现原理,另外两个数组的原子类实现原理与之类似。
7.6 Striped64与LongAdder
从JDK 8开始,针对Long型的原子操作,Java又提供了LongAdder、LongAccumulator;针对 Double类型,Java提供了DoubleAdder、DoubleAccumulator。Striped64相关的类的继承层次如下图 所示。
7.6.1LongAdder原理 AtomicLong内部是一个volatile long型变量,由多个线程对这个变量进行CAS操作。多个线程同时对一个变量进行CAS操作,在高并发的场景下仍不够快,如果再要提高性能,该怎么做呢?
把一个变量拆成多份,变为多个变量,有些类似于 ConcurrentHashMap 的分段锁的例子。如下图所示,把一个Long型拆成一个base变量外加多个Cell,每个Cell包装了一个Long型变量。当多个线程并 发累加的时候,如果并发度低,就直接加到base变量上;如果并发度高,冲突大,平摊到这些Cell上。 在最后取值的时候,再把base和这些Cell求sum运算。
以LongAdder的sum()方法为例,如下所示。
由于无论是long,还是double,都是64位的。但因为没有double型的CAS操作,所以是通过把 double型转化成long型来实现的。所以,上面的base和cell[]变量,是位于基类Striped64当中的。英文Striped意为“条带”,也就是分片。
7.6.2最终一致性 在sum求和方法中,并没有对cells[]数组加锁。也就是说,一边有线程对其执行求和操作,一边还 有线程修改数组里的值,也就是最终一致性,而不是强一致性。这也类似于ConcurrentHashMap 中的clear()方法,一边执行清空操作,一边还有线程放入数据,clear()方法调用完毕后再读取,hash map里面可能还有元素。因此,在LongAdder适合高并发的统计场景,而不适合要对某个 Long 型变量进行严格同步的场景。 7.6.3伪共享与缓存行填充 在Cell类的定义中,用了一个独特的注解@sun.misc.Contended,这是JDK 8之后才有的,背后涉及一个很重要的优化原理:伪共享与缓存行填充。
每个 CPU 都有自己的缓存。缓存与主内存进行数据交换的基本单位叫Cache Line(缓存行)。在64位x86架构中,缓存行是64字节,也就是8个Long型的大小。这也意味着当缓存失效,要刷新到主内 存的时候,最少要刷新64字节。
如下图所示,主内存中有变量X、Y、Z(假设每个变量都是一个Long型),被CPU1和CPU2分别读 入自己的缓存,放在了同一行Cache Line里面。当CPU1修改了X变量,它要失效整行Cache Line,也就是往总线上发消息,通知CPU 2对应的Cache Line失效。由于Cache Line是数据交换的基本单位,无法只失效X,要失效就会失效整行的Cache Line,这会导致Y、Z变量的缓存也失效。
虽然只修改了X变量,本应该只失效X变量的缓存,但Y、Z变量也随之失效。Y、Z变量的数据没有修改,本应该很好地被 CPU1 和 CPU2 共享,却没做到,这就是所谓的“伪共享问题”。 问题的原因是,Y、Z和X变量处在了同一行Cache Line里面。要解决这个问题,需要用到所谓的“缓存行填充”,分别在X、Y、Z后面加上7个无用的Long型,填充整个缓存行,让X、Y、Z处在三行不同的缓存行中,如下图所示:
声明一个@jdk.internal.vm.annotation.Contended即可实现缓存行的填充。之所以这个地方要用 缓存行填充,是为了不让Cell[]数组中相邻的元素落到同一个缓存行里。
7.6.4LongAdder核心实现 下面来看LongAdder最核心的累加方法add(long x),自增、自减操作都是通过调用该方法实现的。
当一个线程调用add(x)的时候,首先会尝试使用casBase把x加到base变量上。如果不成功,则再用c.cas(...)方法尝试把 x 加到 Cell 数组的某个元素上。如果还不成功,最后再调用longAccumulate(...)方法。
注意:Cell[]数组的大小始终是2的整数次方,在运行中会不断扩容,每次扩容都是增长2倍。上面代 码中的cs[getProbe() & m] 其实就是对数组的大小取模。因为m=cs.length–1,getProbe()为该线程生成一个随机数,用该随机数对数组的长度取模。因为数组长度是2的整数次方,所以可以用&操作来优 化取模运算。 对于一个线程来说,它并不在意到底是把x累加到base上面,还是累加到Cell[]数组上面,只要累加 成功就可以。因此,这里使用随机数来实现Cell的长度取模。
如果两次尝试都不成功,则调用 longAccumulate(...)方法,该方法在 Striped64 里面 LongAccumulator也会用到,如下所示。
1final void longAccumulate(long x, LongBinaryOperator fn, 2boolean wasUncontended) { 3int h; 4if ((h = getProbe()) == 0) { 5ThreadLocalRandom.current(); // force initialization 6h = getProbe(); 7wasUncontended = true; 8 } 9// true表示最后一个slot非空 10boolean collide = false; 11done: for (;;) { 12Cell[] cs; Cell c; int n; long v; 13// 如果cells不是null,且cells长度大于0 14if ((cs = cells) != null && (n = cs.length) > 0) { 15// cells最大下标对随机数取模,得到新下标。 16// 如果此新下标处的元素是null 17 if ((c = cs[(n - 1) & h]) == null) { 18// 自旋锁标识,用于创建cells或扩容cells 19if (cellsBusy == 0) { // 尝试添加新的Cell 20Cell r = new Cell(x); // Optimistically create 21// 如果cellsBusy为0,则CAS操作cellsBusy为1,获取锁 22if (cellsBusy == 0 && casCellsBusy()) { 23try { // 获取锁之后,再次检查 24Cell[] rs; int m, j; 25if ((rs = cells) != null &&
26 27 28 29 30 31 }
(m = rs.length) > 0 && rs[j = (m - 1) & h] == null) { // 赋值成功,返回rs[j] = r; break done;
32 33 34 35 36 37 38 }
} finally { // 重置标志位,释放锁 cellsBusy = 0; } continue; // 如果slot非空,则进入下一次循环 }
39 40 }
collide = false;
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 }
else if (!wasUncontended) // CAS操作失败wasUncontended = true; // rehash之后继续 else if (c.cas(v = c.value, (fn == null) ? v + x : fn.applyAsLong(v, x))) break; else if (n >= NCPU || cells != cs) collide = false; // At max size or stale else if (!collide) collide = true; else if (cellsBusy == 0 && casCellsBusy()) { try { if (cells == cs) // 扩容,每次都是上次的两倍长度 cells = Arrays.copyOf(cs, n << 1); } finally { cellsBusy = 0; } collide = false; continue; // Retry with expanded table } h = advanceProbe(h);
62// 如果cells为null或者cells的长度为0,则需要初始化cells数组 63// 此时需要加锁,进行CAS操作 64else if (cellsBusy == 0 && cells == cs && casCellsBusy()) { 65try { // Initialize table 66if (cells == cs) { 67// 实例化Cell数组,实例化Cell,保存x值 68Cell[] rs = new Cell[2]; 69// h为随机数,对Cells数组取模,赋值新的Cell对象。 70rs[h & 1] = new Cell(x); 71cells = rs; 72break done; 73 } 74} finally { 75// 释放CAS锁 76cellsBusy = 0; 77 } 78 } 79// 如果CAS操作失败,最后回到对base的操作 80// 判断fn是否为null,如果是null则执行加操作,否则执行fn提供的操作 81// 如果操作失败,则重试for循环流程,成功就退出循环 82else if (casBase(v = base, 83(fn == null) ? v + x : fn.applyAsLong(v, x)))
7.6.5LongAccumulator LongAccumulator的原理和LongAdder类似,只是功能更强大,下面为两者构造方法的对比:
LongAdder只能进行累加操作,并且初始值默认为0;LongAccumulator可以自己定义一个二元操 作符,并且可以传入一个初始值。
操作符的左值,就是base变量或者Cells[]中元素的当前值;右值,就是add()方法传入的参数x。
下面是LongAccumulator的accumulate(x)方法,与LongAdder的add(x)方法类似,最后都是调用 的Striped64的LongAccumulate(...)方法。 唯一的差别就是LongAdder的add(x)方法调用的是casBase(b, b+x),这里调用的是casBase(b, r), 其中,r=function.applyAsLong(b=base, x)。
7.6.6DoubleAdder与DoubleAccumulator DoubleAdder 其实也是用 long 型实现的,因为没有 double 类型的 CAS 方法。下面是DoubleAdder的add(x)方法,和LongAdder的add(x)方法基本一样,只是多了long和double类型的相互 转换。
其中的关键Double.doubleToRawLongBits(Double.longBitsToDouble(b) + x),在读出来的时候, 它把 long 类型转换成 double 类型,然后进行累加,累加的结果再转换成 long 类型,通过CAS写回 去。
DoubleAccumulate也是Striped64的成员方法,和longAccumulate类似,也是多了long类型和double类型的互相转换。 DoubleAccumulator和DoubleAdder的关系,与LongAccumulator和LongAdder的关系类似,只 是多了一个二元操作符。
8. Lock与Condition
8.1 互斥锁
8.1.1锁的可重入性 “可重入锁”是指当一个线程调用 object.lock()获取到锁,进入临界区后,再次调用object.lock(),仍然可以获取到该锁。显然,通常的锁都要设计成可重入的,否则就会发生死锁。
synchronized关键字,就是可重入锁。如下所示: 在一个synchronized方法method1()里面调用另外一个synchronized方法method2()。如果 synchronized关键字不可重入,那么在method2()处就会发生阻塞,这显然不可行。
8.1.2类继承层次 在正式介绍锁的实现原理之前,先看一下 Concurrent 包中的与互斥锁(ReentrantLock)相关类之间的继承层次,如下图所示:
Lock是一个接口,其定义如下:
常用的方法是lock()/unlock()。lock()不能被中断,对应的lockInterruptibly()可以被中断。
ReentrantLock本身没有代码逻辑,实现都在其内部类Sync中:
8.1.3锁的公平性vs.非公平性 Sync是一个抽象类,它有两个子类FairSync与NonfairSync,分别对应公平锁和非公平锁。从下面 的ReentrantLock构造方法可以看出,会传入一个布尔类型的变量fair指定锁是公平的还是非公平的,默 认为非公平的。
什么叫公平锁和非公平锁呢?先举个现实生活中的例子,一个人去火车站售票窗口买票,发现现场 有人排队,于是他排在队伍末尾,遵循先到者优先服务的规则,这叫公平;如果他去了不排队,直接冲 到窗口买票,这叫作不公平。
对应到锁的例子,一个新的线程来了之后,看到有很多线程在排队,自己排到队伍末尾,这叫公 平;线程来了之后直接去抢锁,这叫作不公平。默认设置的是非公平锁,其实是为了提高效率,减少线 程切换。
锁实现的基本原理 Sync的父类AbstractQueuedSynchronizer经常被称作队列同步器(AQS),这个类非常重要,该 类的父类是AbstractOwnableSynchronizer。 此处的锁具备synchronized功能,即可以阻塞一个线程。为了实现一把具有阻塞或唤醒功能的锁, 需要几个核心要素: 1.需要一个state变量,标记该锁的状态。state变量至少有两个值:0、1。对state变量的操作, 使用CAS保证线程安全。 2.需要记录当前是哪个线程持有锁。 3.需要底层支持对一个线程进行阻塞或唤醒操作。 4.需要有一个队列维护所有阻塞的线程。这个队列也必须是线程安全的无锁队列,也需要使用 CAS。
针对要素1和2,在上面两个类中有对应的体现:
state取值不仅可以是0、1,还可以大于1,就是为了支持锁的可重入性。例如,同样一个线程,调 用5次lock,state会变成5;然后调用5次unlock,state减为0。 当state=0时,没有线程持有锁,exclusiveOwnerThread=null; 当state=1时,有一个线程持有锁,exclusiveOwnerThread=该线程; 当state > 1时,说明该线程重入了该锁。 对于要素3,Unsafe类提供了阻塞或唤醒线程的一对操作原语,也就是park/unpark。
有一个LockSupport的工具类,对这一对原语做了简单封装:
在当前线程中调用park(),该线程就会被阻塞;在另外一个线程中,调用unpark(Thread thread),传入一个被阻塞的线程,就可以唤醒阻塞在park()地方的线程。
unpark(Thread thread),它实现了一个线程对另外一个线程的“精准唤醒”。notify也只是唤醒某一个线程,但无法指定具体唤醒哪个线程。 针对要素4,在AQS中利用双向链表和CAS实现了一个阻塞队列。如下所示:
阻塞队列是整个AQS核心中的核心。如下图所示,head指向双向链表头部,tail指向双向链表尾 部。入队就是把新的Node加到tail后面,然后对tail进行CAS操作;出队就是对head进行CAS操作,把head向后移一个位置。
初始的时候,head=tail=NULL;然后,在往队列中加入阻塞的线程时,会新建一个空的Node,让head和tail都指向这个空Node;之后,在后面加入被阻塞的线程对象。所以,当head=tail的时候,说 明队列为空。
8.1.4公平与非公平的lock()实现差异 下面分析基于AQS,ReentrantLock在公平性和非公平性上的实现差异。
8.1.5阻塞队列与唤醒机制 下面进入锁的最为关键的部分,即acquireQueued(...)方法内部一探究竟。
先说addWaiter(...)方法,就是为当前线程生成一个Node,然后把Node放入双向链表的尾部。要注 意的是,这只是把Thread对象放入了一个队列中而已,线程本身并未阻塞。
创建节点,尝试将节点追加到队列尾部。获取tail节点,将tail节点的next设置为当前节点。 如果tail不存在,就初始化队列。 在addWaiter(...)方法把Thread对象加入阻塞队列之后的工作就要靠acquireQueued(...)方法完成。 线程一旦进入acquireQueued(...)就会被无限期阻塞,即使有其他线程调用interrupt()方法也不能将其唤 醒,除非有其他线程释放了锁,并且该线程拿到了锁,才会从accquireQueued(...)返回。
进入acquireQueued(...),该线程被阻塞。在该方法返回的一刻,就是拿到锁的那一刻,也就是被唤 醒的那一刻,此时会删除队列的第一个元素(head指针前移1个节点)。
首先,acquireQueued(...)方法有一个返回值,表示什么意思呢?虽然该方法不会中断响应,但它会 记录被阻塞期间有没有其他线程向它发送过中断信号。如果有,则该方法会返回true;否则,返回 false。
基于这个返回值,才有了下面的代码:
当 acquireQueued(...)返回 true 时,会调用 selfInterrupt(),自己给自己发送中断信号,也就是自己把自己的中断标志位设为true。之所以要这么做,是因为自己在阻塞期间,收到其他线程中断信号没 有及时响应,现在要进行补偿。这样一来,如果该线程在lock代码块内部有调用sleep()之类的阻塞方 法,就可以抛出异常,响应该中断信号。
阻塞就发生在下面这个方法中: 线程调用 park()方法,自己把自己阻塞起来,直到被其他线程唤醒,该方法返回。park()方法返回有两种情况。 1.其他线程调用了unpark(Thread t)。 2.其他线程调用了t.interrupt()。这里要注意的是,lock()不能响应中断,但LockSupport.park() 会响应中断。
也正因为LockSupport.park()可能被中断唤醒,acquireQueued(...)方法才写了一个for死循环。唤 醒之后,如果发现自己排在队列头部,就去拿锁;如果拿不到锁,则再次自己阻塞自己。不断重复此过 程,直到拿到锁。
被唤醒之后,通过Thread.interrupted()来判断是否被中断唤醒。如果是情况1,会返回false;如果 是情况2,则返回true。
8.1.6unlock()实现分析 说完了lock,下面分析unlock的实现。unlock不区分公平还是非公平。
上图中,当前线程要释放锁,先调用tryRelease(arg)方法,如果返回true,则取出head,让head获 取锁。 对于tryRelease方法: 首先计算当前线程释放锁后的state值。 如果当前线程不是排他线程,则抛异常,因为只有获取锁的线程才可以进行释放锁的操作。 此时设置state,没有使用CAS,因为是单线程操作。
再看unparkSuccessor方法:
release()里面做了两件事:tryRelease(...)方法释放锁;unparkSuccessor(...)方法唤醒队列中的后继 者。
8.1.7lockInterruptibly()实现分析 上面的 lock 不能被中断,这里的 lockInterruptibly()可以被中断:
这里的 acquireInterruptibly(...)也是 AQS 的模板方法,里面的 tryAcquire(...)分别被 FairSync和NonfairSync实现。
主要看doAcquireInterruptibly(...)方法:
当parkAndCheckInterrupt()返回true的时候,说明有其他线程发送中断信号,直接抛出 InterruptedException,跳出for循环,整个方法返回。
8.1.8tryLock()实现分析
tryLock()实现基于调用非公平锁的tryAcquire(...),对state进行CAS操作,如果操作成功就拿到锁; 如果操作不成功则直接返回false,也不阻塞。
8.2 读写锁
和互斥锁相比,读写锁(ReentrantReadWriteLock)就是读线程和读线程之间不互斥。 读读不互斥,读写互斥,写写互斥
8.2.1类继承层次 ReadWriteLock是一个接口,内部由两个Lock接口组成。
ReentrantReadWriteLock实现了该接口,使用方式如下:
也就是说,当使用 ReadWriteLock 的时候,并不是直接使用,而是获得其内部的读锁和写锁,然后分别调用lock/unlock。
8.2.2读写锁实现的基本原理 从表面来看,ReadLock和WriteLock是两把锁,实际上它只是同一把锁的两个视图而已。什么叫两 个视图呢?可以理解为是一把锁,线程分成两类:读线程和写线程。读线程和写线程之间不互斥(可以 同时拿到这把锁),读线程之间不互斥,写线程之间互斥。
从下面的构造方法也可以看出,readerLock和writerLock实际共用同一个sync对象。sync对象同互 斥锁一样,分为非公平和公平两种策略,并继承自AQS。
同互斥锁一样,读写锁也是用state变量来表示锁状态的。只是state变量在这里的含义和互斥锁完全 不同。在内部类Sync中,对state变量进行了重新定义,如下所示:
也就是把 state 变量拆成两半,低16位,用来记录写锁。但同一时间既然只能有一个线程写,为什么还需要16位呢?这是因为一个写线程可能多次重入。例如,低16位的值等于5,表示一个写线程重入 了5次。 高16位,用来“读”锁。例如,高16位的值等于5,既可以表示5个读线程都拿到了该锁;也可以表示 一个读线程重入了5次。
为什么要把一个int类型变量拆成两半,而不是用两个int型变量分别表示读锁和写锁的状态呢? 这是因为无法用一次CAS 同时操作两个int变量,所以用了一个int型的高16位和低16位分别表示读锁和写锁的状态。
当state=0时,说明既没有线程持有读锁,也没有线程持有写锁;当state != 0时,要么有线程持有读锁,要么有线程持有写锁,两者不能同时成立,因为读和写互斥。这时再进一步通过sharedCount(state)和exclusiveCount(state)判断到底是读线程还是写线程持有了该锁。
8.2.3AQS的两对模板方法 下面介绍在ReentrantReadWriteLock的两个内部类ReadLock和WriteLock中,是如何使用state变 量的。
acquire/release、acquireShared/releaseShared 是AQS里面的两对模板方法。互斥锁和读写锁的写锁都是基于acquire/release模板方法来实现的。读写锁的读锁是基于acquireShared/releaseShared 这对模板方法来实现的。这两对模板方法的代码如下:
将读/写、公平/非公平进行排列组合,就有4种组合。如下图所示,上面的两个方法都是在Sync中实 现的。Sync中的两个方法又是模板方法,在NonfairSync和FairSync中分别有实现。最终的对应关系如 下: 1.读锁的公平实现:Sync.tryAccquireShared()+FairSync中的两个重写的子方法。 2.读锁的非公平实现:Sync.tryAccquireShared()+NonfairSync中的两个重写的子方法。 3.写锁的公平实现:Sync.tryAccquire()+FairSync中的两个重写的子方法。 4.写锁的非公平实现:Sync.tryAccquire()+NonfairSync中的两个重写的子方法。
1static final class NonfairSync extends Sync { 2private static final long serialVersionUID = -8159625535654395037L; 3// 写线程抢锁的时候是否应该阻塞 4final boolean writerShouldBlock() { 5// 写线程在抢锁之前永远不被阻塞,非公平锁 6return false; 7 } 8// 读线程抢锁的时候是否应该阻塞 9final boolean readerShouldBlock() { 10// 读线程抢锁的时候,当队列中第一个元素是写线程的时候要阻塞 11return apparentlyFirstQueuedIsExclusive(); 12 } 13 } 14 15static final class FairSync extends Sync { 16private static final long serialVersionUID = -2274990926593161451L; 17// 写线程抢锁的时候是否应该阻塞 18final boolean writerShouldBlock() { 19// 写线程在抢锁之前,如果队列中有其他线程在排队,则阻塞。公平锁 20return hasQueuedPredecessors(); 21 } 22// 读线程抢锁的时候是否应该阻塞 23final boolean readerShouldBlock() { 24// 读线程在抢锁之前,如果队列中有其他线程在排队,阻塞。公平锁 25return hasQueuedPredecessors(); 26 } 27 }
对于公平,比较容易理解,不论是读锁,还是写锁,只要队列中有其他线程在排队(排队等读锁, 或者排队等写锁),就不能直接去抢锁,要排在队列尾部。 对于非公平,读锁和写锁的实现策略略有差异。 写线程能抢锁,前提是state=0,只有在没有其他线程持有读锁或写锁的情况下,它才有机会去抢 锁。或者state != 0,但那个持有写锁的线程是它自己,再次重入。写线程是非公平的,即writerShouldBlock()方法一直返回false。
对于读线程,假设当前线程被读线程持有,然后其他读线程还非公平地一直去抢,可能导致写线程 永远拿不到锁,所以对于读线程的非公平,要做一些“约束”。当发现队列的第1个元素是写线程的时候, 读线程也要阻塞,不能直接去抢。即偏向写线程。
8.2.4WriteLock公平vs.非公平实现 写锁是排他锁,实现策略类似于互斥锁。
1.tryLock()实现分析
lock()方法:
在互斥锁部分讲过了。
tryLock和lock方法不区分公平/非公平。
2.unlock()实现分析
unlock()方法不区分公平/非公平。
8.2.5ReadLock公平vs.非公平实现 读锁是共享锁,其实现策略和排他锁有很大的差异。
1.tryLock()实现分析
30 HoldCounter rh = cachedHoldCounter;
31 if (rh == null ||
32 rh.tid != LockSupport.getThreadId(current))
33 cachedHoldCounter = rh = readHolds.get();
34 else if (rh.count == 0)
35 readHolds.set(rh);
36 rh.count++;
37 }
38 return true;
39 }
40 }
41 }
2.unlock()实现分析
tryReleaseShared()的实现:
因为读锁是共享锁,多个线程会同时持有读锁,所以对读锁的释放不能直接减1,而是需要通过一个 for循环+CAS操作不断重试。这是tryReleaseShared和tryRelease的根本差异所在。
8.3 Condition
8.3.1Condition与Lock的关系 Condition本身也是一个接口,其功能和wait/notify类似,如下所示:
wait()/notify()必须和synchronized一起使用,Condition也必须和Lock一起使用。因此,在Lock的 接口中,有一个与Condition相关的接口:
8.3.2Condition的使用场景 以ArrayBlockingQueue为例。如下所示为一个用数组实现的阻塞队列,执行put(...)操作的时候,队 列满了,生产者线程被阻塞;执行take()操作的时候,队列为空,消费者线程被阻塞。
27 28 29 30 31 32 33 34 35 36 37 } 38
final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == items.length) // 非满条件阻塞,队列容量已满 notFull.await(); enqueue(e); } finally { lock.unlock(); }
39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 }
private void enqueue(E e) { // assert lock.isHeldByCurrentThread(); // assert lock.getHoldCount() == 1; // assert items[putIndex] == null; final Object[] items = this.items; items[putIndex] = e; if (++putIndex == items.length) putIndex = 0; count++; // put数据结束,通知消费者非空条件 notEmpty.signal(); }
public E take() throws InterruptedException { final ReentrantLock lock = this.lock; lock.lockInterruptibly(); try { while (count == 0) // 阻塞于非空条件,队列元素个数为0,无法消费 notEmpty.await(); return dequeue(); } finally { lock.unlock(); } }
private E dequeue() { // assert lock.isHeldByCurrentThread(); // assert lock.getHoldCount() == 1; // assert items[takeIndex] != null; final Object[] items = this.items; @SuppressWarnings("unchecked") E e = (E) items[takeIndex]; items[takeIndex] = null; if (++takeIndex == items.length) takeIndex = 0; count--; if (itrs != null) itrs.elementDequeued(); // 消费成功,通知非满条件,队列中有空间,可以生产元素了。 notFull.signal(); return e; } // ...
8.3.3Condition实现原理 可以发现,Condition的使用很方便,避免了wait/notify的生产者通知生产者、消费者通知消费者的 问题。具体实现如下: 由于Condition必须和Lock一起使用,所以Condition的实现也是Lock的一部分。首先查看互斥锁和 读写锁中Condition的构造方法:
首先,读写锁中的 ReadLock 是不支持 Condition 的,读写锁的写锁和互斥锁都支持Condition。虽然它们各自调用的是自己的内部类Sync,但内部类Sync都继承自AQS。因此,上面的代码sync.newCondition最终都调用了AQS中的newCondition:
每一个Condition对象上面,都阻塞了多个线程。因此,在ConditionObject内部也有一个双向链表 组成的队列,如下所示:
下面来看一下在await()/notify()方法中,是如何使用这个队列的。
8.3.4await()实现分析
关于await,有几个关键点要说明: 1.线程调用 await()的时候,肯定已经先拿到了锁。所以,在 addConditionWaiter()内部,对这个双向链表的操作不需要执行CAS操作,线程天生是安全的,代码如下:
1 private Node addConditionWaiter() { 2 // ... 3 Node t = lastWaiter; 4 Node node = new Node(Thread.currentThread(), Node.CONDITION); 5 if (t == null) 6 firstWaiter = node; 7 else 8 t.nextWaiter = node; 9 lastWaiter = node; 10 return node; 11 }
2.在线程执行wait操作之前,必须先释放锁。也就是fullyRelease(node),否则会发生死锁。这 个和wait/notify与synchronized的配合机制一样。 3.线程从wait中被唤醒后,必须用acquireQueued(node, savedState)方法重新拿锁。 4.checkInterruptWhileWaiting(node)代码在park(this)代码之后,是为了检测在park期间是否 收到过中断信号。当线程从park中醒来时,有两种可能:一种是其他线程调用了unpark,另 一种是收到中断信号。这里的await()方法是可以响应中断的,所以当发现自己是被中断唤醒 的,而不是被unpark唤醒的时,会直接退出while循环,await()方法也会返回。 5.isOnSyncQueue(node)用于判断该Node是否在AQS的同步队列里面。初始的时候,Node只 在Condition的队列里,而不在AQS的队列里。但执行notity操作的时候,会放进AQS的同步队 列。
8.3.5awaitUninterruptibly()实现分析 与await()不同,awaitUninterruptibly()不会响应中断,其方法的定义中不会有中断异常抛出,下面 分析其实现和await()的区别。
可以看出,整体代码和 await()类似,区别在于收到异常后,不会抛出异常,而是继续执行while循环。
8.3.6notify()实现分析
同 await()一样,在调用 notify()的时候,必须先拿到锁(否则就会抛出上面的异常),是因为前面执行await()的时候,把锁释放了。
然后,从队列中取出firstWaiter,唤醒它。在通过调用unpark唤醒它之前,先用enq(node)方法把 这个Node放入AQS的锁对应的阻塞队列中。也正因为如此,才有了await()方法里面的判断条件: while( ! isOnSyncQueue(node)) 这个判断条件满足,说明await线程不是被中断,而是被unpark唤醒的。 notifyAll()与此类似。
8.4StampedLock 8.4.1为什么引入StampedLock StampedLock是在JDK8中新增的,有了读写锁,为什么还要引入StampedLock呢?
锁 并发度 ReentrantLock 读读互斥,读写互斥,写写互斥 ReentrantReadWriteLock 读读不互斥,读写互斥,写写互斥 StampedLock 读读不互斥,读写不互斥,写写互斥
可以看到,从ReentrantLock到StampedLock,并发度依次提高。 另一方面,因为ReentrantReadWriteLock采用的是“悲观读”的策略,当第一个读线程拿到锁之后, 第二个、第三个读线程还可以拿到锁,使得写线程一直拿不到锁,可能导致写线程“饿死”。虽然在其公 平或非公平的实现中,都尽量避免这种情形,但还有可能发生。 StampedLock引入了“乐观读”策略,读的时候不加读锁,读出来发现数据被修改了,再升级为“悲观 读”,相当于降低了“读”的地位,把抢锁的天平往“写”的一方倾斜了一下,避免写线程被饿死。
8.4.2使用场景 在剖析其原理之前,下面先以官方的一个例子来看一下StampedLock如何使用。
如上面代码所示,有一个Point类,多个线程调用move()方法,修改坐标;还有多个线程调用 distanceFromOrigin()方法,求距离。
首先,执行move操作的时候,要加写锁。这个用法和ReadWriteLock的用法没有区别,写操作和写 操作也是互斥的。 关键在于读的时候,用了一个“乐观读”sl.tryOptimisticRead(),相当于在读之前给数据的状态做了 一个“快照”。然后,把数据拷贝到内存里面,在用之前,再比对一次版本号。如果版本号变了,则说明 在读的期间有其他线程修改了数据。读出来的数据废弃,重新获取读锁。关键代码就是下面这三行:
要说明的是,这三行关键代码对顺序非常敏感,不能有重排序。因为 state 变量已经是volatile, 所以可以禁止重排序,但stamp并不是volatile的。为此,在validate(stamp)方法里面插入内存屏 障。
8.4.3“乐观读”的实现原理 首先,StampedLock是一个读写锁,因此也会像读写锁那样,把一个state变量分成两半,分别表示 读锁和写锁的状态。同时,它还需要一个数据的version。但是,一次CAS没有办法操作两个变量,所以 这个state变量本身同时也表示了数据的version。下面先分析state变量。
如下图:用最低的8位表示读和写的状态,其中第8位表示写锁的状态,最低的7位表示读锁的状 态。因为写锁只有一个bit位,所以写锁是不可重入的。
初始值不为0,而是把WBIT 向左移动了一位,也就是上面的ORIGIN 常量,构造方法如下所示。
为什么state的初始值不设为0呢?看乐观锁的实现:
上面两个方法必须结合起来看:当state&WBIT != 0的时候,说明有线程持有写锁,上面的tryOptimisticRead会永远返回0。这样,再调用validate(stamp),也就是validate(0)也会永远返 回false。这正是我们想要的逻辑:当有线程持有写锁的时候,validate永远返回false,无论写线程是否 释放了写锁。因为无论是否释放了(state回到初始值)写锁,state值都不为0,所以validate(0)永远 为false。 为什么上面的validate(...)方法不直接比较stamp=state,而要比较state&SBITS=state&SBITS 呢? 因为读锁和读锁是不互斥的! 所以,即使在“乐观读”的时候,state 值被修改了,但如果它改的是第7位,validate(...)还是会返回 true。 另外要说明的一点是,上面使用了内存屏障VarHandle.acquireFence();,是因为在这行代码的下一 行里面的stamp、SBITS变量不是volatile的,由此可以禁止其和前面的currentX=X,currentY=Y进行重 排序。 通过上面的分析,可以发现state的设计非常巧妙。只通过一个变量,既实现了读锁、写锁的状态记 录,还实现了数据的版本号的记录。
8.4.4悲观读/写:“阻塞”与“自旋”策略实现差异 同ReadWriteLock一样,StampedLock也要进行悲观的读锁和写锁操作。不过,它不是基于AQS实 现的,而是内部重新实现了一个阻塞队列。如下所示。
这个阻塞队列和 AQS 里面的很像。 刚开始的时候,whead=wtail=NULL,然后初始化,建一个空节点,whead和wtail都指向这个空节 点,之后往里面加入一个个读线程或写线程节点。 但基于这个阻塞队列实现的锁的调度策略和AQS很不一样,也就是“自旋”。 在AQS里面,当一个线程CAS state失败之后,会立即加入阻塞队列,并且进入阻塞状态。 但在StampedLock中,CAS state失败之后,会不断自旋,自旋足够多的次数之后,如果还拿不到锁,才进入阻塞状态。 为此,根据CPU的核数,定义了自旋次数的常量值。如果是单核的CPU,肯定不能自旋,在多核情 况下,才采用自旋策略。
下面以写锁的加锁,也就是StampedLock的writeLock()方法为例,来看一下自旋的实现。
如上面代码所示,当state&ABITS==0的时候,说明既没有线程持有读锁,也没有线程持有写锁,此 时当前线程才有资格通过CAS操作state。若操作不成功,则调用acquireWrite()方法进入阻塞队列,并 进行自旋,这个方法是整个加锁操作的核心,代码如下:
3 for (int spins = -1;;) { // 入列时自旋
4 long m, s, ns;
5 if ((m = (s = state) & ABITS) == 0L) {
6 if ((ns = tryWriteLock(s)) != 0L)
7 return ns; // 自旋的时候获取到锁,返回
8 }
9 else if (spins < 0)
10 // 计算自旋值
11 spins = (m == WBIT && wtail == whead) ? SPINS : 0;
12 else if (spins > 0) {
13 --spins; // 每次自旋获取锁,spins值减一
14 Thread.onSpinWait();
15 }
16 else if ((p = wtail) == null) { // 如果尾部节点是null,初始化队列
17 WNode hd = new WNode(WMODE, null);
18 // 头部和尾部指向一个节点
19 if (WHEAD.weakCompareAndSet(this, null, hd))
20 wtail = hd;
21 }
22 else if (node == null)
23 node = new WNode(WMODE, p);
24 else if (node.prev != p)
25 // p节点作为前置节点
26 node.prev = p;
27 // for循环唯一的break,成功将节点node添加到队列尾部,才会退出for循环
28 else if (WTAIL.weakCompareAndSet(this, p, node)) {
29 // 设置p的后置节点为node
30 p.next = node;
31 break;
32 }
33 }
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60 boolean wasInterrupted = false; for (int spins = -1;;) {
WNode h, np, pp; int ps; if ((h = whead) == p) {
if (spins < 0)
spins = HEAD_SPINS;
else if (spins < MAX_HEAD_SPINS) spins <<= 1;
for (int k = spins; k > 0; --k) { // spin at head long s, ns;
if (((s = state) & ABITS) == 0L) {
if ((ns = tryWriteLock(s)) != 0L) { whead = node;
node.prev = null; if (wasInterrupted)
Thread.currentThread().interrupt(); return ns;
}
}
else
Thread.onSpinWait();
}
}
else if (h != null) { // 唤醒读取的线程
WNode c; Thread w;
while ((c = h.cowait) != null) {
61 62 63 64 65 }
if (WCOWAIT.weakCompareAndSet(h, c, c.cowait) && (w = c.thread) != null) LockSupport.unpark(w); }
66if (whead == h) { 67if ((np = node.prev) != p) { 68if (np != null) 69(p = np).next = node; // stale 70 } 71else if ((ps = p.status) == 0) 72WSTATUS.compareAndSet(p, 0, WAITING); 73else if (ps == CANCELLED) { 74if ((pp = p.prev) != null) { 75node.prev = pp; 76pp.next = node; 77 } 78 } 79else { 80long time; // 0 argument to park means no timeout 81if (deadline == 0L) 82time = 0L; 83else if ((time = deadline - System.nanoTime()) <= 0L) 84return cancelWaiter(node, node, false); 85Thread wt = Thread.currentThread(); 86node.thread = wt; 87if (p.status < 0 && (p != h || (state & ABITS) != 0L) && 88whead == h && node.prev == p) { 89if (time == 0L) 90// 阻塞,直到被唤醒 91LockSupport.park(this); 92else 93// 计时阻塞 94LockSupport.parkNanos(this, time); 95 } 96node.thread = null; 97if (Thread.interrupted()) { 98if (interruptible) 99// 如果被中断了,则取消等待 100return cancelWaiter(node, node, true);
101 wasInterrupted = true;
102 }
103 }
104 }
105 }
106 }
107
108
整个acquireWrite(...)方法是两个大的for循环,内部实现了非常复杂的自旋策略。在第一个大的for 循环里面,目的就是把该Node加入队列的尾部,一边加入,一边通过CAS操作尝试获得锁。如果获得 了,整个方法就会返回;如果不能获得锁,会一直自旋,直到加入队列尾部。
在第二个大的for循环里,也就是该Node已经在队列尾部了。这个时候,如果发现自己刚好也在队 列头部,说明队列中除了空的Head节点,就是当前线程了。此时,再进行新一轮的自旋,直到达到MAX_HEAD_SPINS次数,然后进入阻塞。这里有一个关键点要说明:当release(...)方法被调用之后,会 唤醒队列头部的第1个元素,此时会执行第二个大的for循环里面的逻辑,也就是接着for循环里面park() 方法后面的代码往下执行。
另外一个不同于AQS的阻塞队列的地方是,在每个WNode里面有一个cowait指针,用于串联起所有 的读线程。例如,队列尾部阻塞的是一个读线程 1,现在又来了读线程 2、3,那么会通过cowait指针, 把1、2、3串联起来。1被唤醒之后,2、3也随之一起被唤醒,因为读和读之间不互斥。
明白加锁的自旋策略后,下面来看锁的释放操作。和读写锁的实现类似,也是做了两件事情:一是 把state变量置回原位,二是唤醒阻塞队列中的第一个节点。
第三部分:线程池与Future
9. 线程池的实现原理
下图所示为线程池的实现原理:调用方不断地向线程池中提交任务;线程池中有一组线程,不断地 从队列中取任务,这是一个典型的生产者—消费者模型。
要实现这样一个线程池,有几个问题需要考虑: 1.队列设置多长?如果是无界的,调用方不断地往队列中放任务,可能导致内存耗尽。如果是有 界的,当队列满了之后,调用方如何处理? 2.线程池中的线程个数是固定的,还是动态变化的? 3.每次提交新任务,是放入队列?还是开新线程? 4.当没有任务的时候,线程是睡眠一小段时间?还是进入阻塞?如果进入阻塞,如何唤醒?
针对问题4,有3种做法: 1.不使用阻塞队列,只使用一般的线程安全的队列,也无阻塞/唤醒机制。当队列为空时,线程 池中的线程只能睡眠一会儿,然后醒来去看队列中有没有新任务到来,如此不断轮询。 2.不使用阻塞队列,但在队列外部、线程池内部实现了阻塞/唤醒机制。 3.使用阻塞队列。
很显然,做法3最完善,既避免了线程池内部自己实现阻塞/唤醒机制的麻烦,也避免了做法1的睡 眠/轮询带来的资源消耗和延迟。正因为如此,接下来要讲的 ThreadPoolExector/ScheduledThreadPoolExecutor都是基于阻塞队列来实现的,而不是一般的队列, 至此,各式各样的阻塞队列就要派上用场了。
10. 线程池的类继承体系
线程池的类继承体系如下图所示:
在这里,有两个核心的类: ThreadPoolExector 和ScheduledThreadPoolExecutor ,后者不仅可以执行某个任务,还可以周期性地执行任务。 向线程池中提交的每个任务,都必须实现Runnable 接口,通过最上面的Executor 接口中的 execute(Runnable command) 向线程池提交任务。 然后,在 中,定义了线程池的关闭接口 shutdown() ,还定义了可以有返回值 的任务,也就是Callable ,后面会详细介绍。
11. ThreadPoolExecutor
11.1 核心数据结构
基于线程池的实现原理,下面看一下ThreadPoolExector的核心数据结构。
每一个线程是一个Worker对象。Worker是ThreadPoolExector的内部类,核心数据结构如下:
由定义会发现,Worker继承于AQS,也就是说Worker本身就是一把锁。这把锁有什么用处呢?用 于线程池的关闭、线程执行任务的过程中。
11.2 核心配置参数解释
ThreadPoolExecutor在其构造方法中提供了几个核心配置参数,来配置不同策略的线程池。
上面的各个参数,解释如下: 1.corePoolSize:在线程池中始终维护的线程个数。 2.maxPoolSize:在corePooSize已满、队列也满的情况下,扩充线程至此值。 3.keepAliveTime/TimeUnit:maxPoolSize 中的空闲线程,销毁所需要的时间,总线程数收缩回corePoolSize。 4.blockingQueue:线程池所用的队列类型。 5.threadFactory:线程创建工厂,可以自定义,有默认值
6.RejectedExecutionHandler:corePoolSize已满,队列已满,maxPoolSize 已满,最后的拒绝策略。
下面来看这6个配置参数在任务的提交过程中是怎么运作的。在每次往线程池中提交任务的时候,有 如下的处理流程: 步骤一:判断当前线程数是否大于或等于corePoolSize。如果小于,则新建线程执行;如果大于, 则进入步骤二。 步骤二:判断队列是否已满。如未满,则放入;如已满,则进入步骤三。 步骤三:判断当前线程数是否大于或等于maxPoolSize。如果小于,则新建线程执行;如果大于, 则进入步骤四。 步骤四:根据拒绝策略,拒绝任务。
总结一下:首先判断corePoolSize,其次判断blockingQueue是否已满,接着判断maxPoolSize, 最后使用拒绝策略。 很显然,基于这种流程,如果队列是无界的,将永远没有机会走到步骤三,也即maxPoolSize没有 使用,也一定不会走到步骤四。
11.3 线程池的优雅关闭
线程池的关闭,较之线程的关闭更加复杂。当关闭一个线程池的时候,有的线程还正在执行某个任 务,有的调用者正在向线程池提交任务,并且队列中可能还有未执行的任务。因此,关闭过程不可能是 瞬时的,而是需要一个平滑的过渡,这就涉及线程池的完整生命周期管理。
1.线程池的生命周期 在JDK 7中,把线程数量(workerCount)和线程池状态(runState)这两个变量打包存储在一个字段里面,即ctl变量。如下图所示,最高的3位存储线程池状态,其余29位存储线程个数。而在JDK 6中, 这两个变量是分开存储的。
由上面的代码可以看到,ctl变量被拆成两半,最高的3位用来表示线程池的状态,低的29位表示线 程的个数。线程池的状态有五种,分别是RUNNING、SHUTDOWN、STOP、TIDYING和TERMINATED。
下面分析状态之间的迁移过程,如图所示:
线程池有两个关闭方法,shutdown()和shutdownNow(),这两个方法会让线程池切换到不同的状 态。在队列为空,线程池也为空之后,进入TIDYING 状态;最后执行一个钩子方法terminated(),进入TERMINATED状态,线程池才真正关闭。 这里的状态迁移有一个非常关键的特征:从小到大迁移,-1,0,1,2,3,只会从小的状态值往大 的状态值迁移,不会逆向迁移。例如,当线程池的状态在TIDYING=2时,接下来只可能迁移到TERMINATED=3,不可能迁移回STOP=1或者其他状态。 除 terminated()之外,线程池还提供了其他几个钩子方法,这些方法的实现都是空的。如果想实现自己的线程池,可以重写这几个方法:
2.正确关闭线程池的步骤
关闭线程池的过程为:在调用 shutdown()或者shutdownNow()之后,线程池并不会立即关闭,接下来需要调用 awaitTermination() 来等待线程池关闭。关闭线程池的正确步骤如下:
awaitTermination(...)方法的内部实现很简单,如下所示。不断循环判断线程池是否到达了最终状态TERMINATED,如果是,就返回;如果不是,则通过termination条件变量阻塞一段时间,之后继续判 断。
3.shutdown()与shutdownNow()的区别
1.shutdown()不会清空任务队列,会等所有任务执行完成,shutdownNow()清空任务队列。 2.shutdown()只会中断空闲的线程,shutdownNow()会中断所有线程。
下面看一下在上面的代码里中断空闲线程和中断所有线程的区别。
shutdown()方法中的interruptIdleWorkers()方法的实现:
关键区别点在tryLock():一个线程在执行一个任务之前,会先加锁,这意味着通过是否持有锁,可 以判断出线程是否处于空闲状态。tryLock()如果调用成功,说明线程处于空闲状态,向其发送中断信 号;否则不发送。 tryLock()方法
tryAcquire方法:
shutdownNow()调用了 interruptWorkers(); 方法:
interruptIfStarted() 方法的实现:
在上面的代码中,shutdown() 和shutdownNow()都调用了tryTerminate()方法,如下所示:
tryTerminate()不会强行终止线程池,只是做了一下检测:当workerCount为0,workerQueue为 空时,先把状态切换到TIDYING,然后调用钩子方法terminated()。当钩子方法执行完成时,把状态从TIDYING 改为 TERMINATED,接着调用termination.sinaglAll(),通知前面阻塞在awaitTermination的所有调用者线程。 所以,TIDYING和TREMINATED的区别是在二者之间执行了一个钩子方法terminated(),目前是一 个空实现。
11.4 任务的提交过程分析
提交任务的方法如下:
7 8 9 10 11 }
// 添加Worker,并将command设置为Worker线程的第一个任务开始执行。 if (addWorker(command, true)) return; c = ctl.get();
12 13 14 15 16 17 18 19 20 21 22 23 24 25 } 26
// 如果当前的线程数大于或等于corePoolSize,则调用workQueue.offer放入队列 if (isRunning(c) && workQueue.offer(command)) { int recheck = ctl.get(); // 如果线程池正在停止,则将command任务从队列移除,并拒绝command任务请求。 if (! isRunning(recheck) && remove(command)) reject(command); // 放入队列中后发现没有线程执行任务,开启新线程 else if (workerCountOf(recheck) == 0) addWorker(null, false); } // 线程数大于maxPoolSize,并且队列已满,调用拒绝策略 else if (!addWorker(command, false)) reject(command);
27// 该方法用于启动新线程。如果第二个参数为true,则使用corePoolSize作为上限,否则使用 maxPoolSize作为上限。 28private boolean addWorker(Runnable firstTask, boolean core) { 29retry: 30for (int c = ctl.get();;) { 31 // 如果线程池状态值起码是SHUTDOWN和STOP,或则第一个任务不是null,或者工作队列为空 32// 则添加worker失败,返回false 33if (runStateAtLeast(c, SHUTDOWN) 34&& (runStateAtLeast(c, STOP) 35|| firstTask != null 36|| workQueue.isEmpty())) 37return false; 38 39 for (;;) { 40 // 工作线程数达到上限,要么是corePoolSize要么是maximumPoolSize,启动线程失败 41if (workerCountOf(c) 42>= ((core ? corePoolSize : maximumPoolSize) & COUNT_MASK)) 43return false; 44// 增加worker数量成功,返回到retry语句 45if (compareAndIncrementWorkerCount(c)) 46break retry; 47c = ctl.get(); // Re-read ctl 48// 如果线程池运行状态起码是SHUTDOWN,则重试retry标签语句,CAS 49if (runStateAtLeast(c, SHUTDOWN)) 50continue retry; 51// else CAS failed due to workerCount change; retry inner loop 52 } 53 } 54// worker数量加1成功后,接着运行: 55boolean workerStarted = false; 56boolean workerAdded = false; 57Worker w = null; 58try { 59// 新建worker对象 60w = new Worker(firstTask); 61// 获取线程对象
11.5 任务的执行过程分析
在上面的任务提交过程中,可能会开启一个新的Worker,并把任务本身作为firstTask赋给该Worker。但对于一个Worker来说,不是只执行一个任务,而是源源不断地从队列中取任务执行,这是 一个不断循环的过程。
下面来看Woker的run()方法的实现过程。
4// 线程需要运行的第一个任务。可以是null,如果是null,则线程从队列获取任务 5Runnable firstTask; 6// 记录线程执行完成的任务数量,每个线程一个计数器 7volatile long completedTasks; 8 9 /* 10 使用给定的第一个任务并利用线程工厂创建Worker实例 11 @param firstTask 线程的第一个任务,如果没有,就设置为null,此时线程会从队列获取任务。 12 / 13Worker(Runnable firstTask) { 14setState(-1); // 线程处于阻塞状态,调用runWorker的时候中断 15this.firstTask = firstTask; 16this.thread = getThreadFactory().newThread(this); 17 } 18 19// 调用ThreadPoolExecutor的runWorker方法执行线程的运行 20public void run() { 21runWorker(this); 22 } 23 } 24 25final void runWorker(Worker w) { 26Thread wt = Thread.currentThread(); 27Runnable task = w.firstTask; 28w.firstTask = null; 29// 中断Worker封装的线程 30w.unlock(); 31boolean completedAbruptly = true; 32try { 33 // 如果线程初始任务不是null,或者从队列获取的任务不是null,表示该线程应该执行任务。 34while (task != null || (task = getTask()) != null) { 35// 获取线程锁 36w.lock(); 37// 如果线程池停止了,确保线程被中断 38// 如果线程池正在运行,确保线程不被中断 39if ((runStateAtLeast(ctl.get(), STOP) || 40(Thread.interrupted() && 41runStateAtLeast(ctl.get(), STOP))) && 42!wt.isInterrupted()) 43 // 获取到任务后,再次检查线程池状态,如果发现线程池已经停止,则给自己发中断信号 44wt.interrupt(); 45try { 46// 任务执行之前的钩子方法,实现为空 47beforeExecute(wt, task); 48try { 49task.run(); 50// 任务执行结束后的钩子方法,实现为空 51afterExecute(task, null); 52} catch (Throwable ex) { 53afterExecute(task, ex); 54throw ex; 55 } 56} finally { 57// 任务执行完成,将task设置为null 58task = null;
1.shutdown()与任务执行过程综合分析
把任务的执行过程和上面的线程池的关闭过程结合起来进行分析,当调用 shutdown()的时候,可能出现以下几种场景: 1.当调用shutdown()的时候,所有线程都处于空闲状态。 这意味着任务队列一定是空的。此时,所有线程都会阻塞在 getTask()方法的地方。然后,所有线程都会收到interruptIdleWorkers()发来的中断信号,getTask()返回null,所有Worker都 会退出while循环,之后执行processWorkerExit。
2.当调用shutdown()的时候,所有线程都处于忙碌状态。 此时,队列可能是空的,也可能是非空的。interruptIdleWorkers()内部的tryLock调用失败, 什么都不会做,所有线程会继续执行自己当前的任务。之后所有线程会执行完队列中的任务, 直到队列为空,getTask()才会返回null。之后,就和场景1一样了,退出while循环。
3.当调用shutdown()的时候,部分线程忙碌,部分线程空闲。 有部分线程空闲,说明队列一定是空的,这些线程肯定阻塞在 getTask()方法的地方。空闲的这些线程会和场景1一样处理,不空闲的线程会和场景2一样处理。
下面看一下getTask()方法的内部细节:
2.shutdownNow() 与任务执行过程综合分析
和上面的 shutdown()类似,只是多了一个环节,即清空任务队列。如果一个线程正在执行某个业务代码,即使向它发送中断信号,也没有用,只能等它把代码执行完成。因此,中断空闲线程和中断所有 线程的区别并不是很大,除非线程当前刚好阻塞在某个地方。
当一个Worker最终退出的时候,会执行清理工作:
11.6 线程池的4种拒绝策略
在execute(Runnable command)的最后,调用了reject(command)执行拒绝策略,代码如下所示:
handler就是我们可以设置的拒绝策略管理器:
RejectedExecutionHandler 是一个接口,定义了四种实现,分别对应四种不同的拒绝策略,默认是 AbortPolicy。
ThreadPoolExecutor类中默认的实现是:
四种策略的实现代码如下: 策略1:调用者直接在自己的线程里执行,线程池不处理,比如到医院打点滴,医院没地方了,到你 家自己操作吧:
策略2:线程池抛异常:
策略3:线程池直接丢掉任务,神不知鬼不觉:
策略4:删除队列中最早的任务,将当前任务入队列:
示例程序:
12. Executors工具类
concurrent包提供了Executors工具类,利用它可以创建各种不同类型的线程池。
12.1 四种对比
单线程的线程池:
固定数目线程的线程池:
每接收一个请求,就创建一个线程来执行:
单线程具有周期调度功能的线程池:
多线程,有调度功能的线程池:
12.2 最佳实践
不同类型的线程池,其实都是由前面的几个关键配置参数配置而成的。 在《阿里巴巴Java开发手册》中,明确禁止使用Executors创建线程池,并要求开发者直接使用 ThreadPoolExector或ScheduledThreadPoolExecutor进行创建。这样做是为了强制开发者明确线程池 的运行策略,使其对线程池的每个配置参数皆做到心中有数,以规避因使用不当而造成资源耗尽的风 险。
13. ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor实现了按时间调度来执行任务: 1.延迟执行任务
2.周期执行任务
区别如下: AtFixedRate:按固定频率执行,与任务本身执行时间无关。但有个前提条件,任务执行时间必须小 于间隔时间,例如间隔时间是5s,每5s执行一次任务,任务的执行时间必须小于5s。 WithFixedDelay:按固定间隔执行,与任务本身执行时间有关。例如,任务本身执行时间是10s, 间隔2s,则下一次开始执行的时间就是12s。
13.1 延迟执行和周期性执行的原理
ScheduledThreadPoolExecutor继承了ThreadPoolExecutor,这意味着其内部的数据结构和ThreadPoolExecutor是基本一样的,那它是如何实现延迟执行任务和周期性执行任务的呢? 延迟执行任务依靠的是DelayQueue。DelayQueue是 BlockingQueue的一种,其实现原理是二叉堆。 而周期性执行任务是执行完一个任务之后,再把该任务扔回到任务队列中,如此就可以对一个任务 反复执行。 不过这里并没有使用DelayQueue,而是在ScheduledThreadPoolExecutor内部又实现了一个特定 的DelayQueue。
其原理和DelayQueue一样,但针对任务的取消进行了优化。下面主要讲延迟执行和周期性执行的 实现过程。
13.2 延迟执行
传进去的是一个Runnable,外加延迟时间delay。在内部通过decorateTask(...)方法把Runnable包 装成一个ScheduleFutureTask对象,而DelayedWorkQueue中存放的正是这种类型的对象,这种类型 的对象一定实现了Delayed接口。
从上面的代码中可以看出,schedule()方法本身很简单,就是把提交的Runnable任务加上delay时 间,转换成ScheduledFutureTask对象,放入DelayedWorkerQueue中。任务的执行过程还是复用的ThreadPoolExecutor,延迟的控制是在DelayedWorkerQueue内部完成的。
13.3 周期性执行
和schedule(...)方法的框架基本一样,也是包装一个ScheduledFutureTask对象,只是在延迟时间参 数之外多了一个周期参数,然后放入DelayedWorkerQueue就结束了。
两个方法的区别在于一个传入的周期是一个负数,另一个传入的周期是一个正数,为什么要这样做 呢?
用于生成任务序列号的sequencer,创建ScheduledFutureTask的时候使用:
1private class ScheduledFutureTask
withFixedDelay和atFixedRate的区别就体现在setNextRunTime里面。 如果是atFixedRate,period>0,下一次开始执行时间等于上一次开始执行时间+period; 如果是withFixedDelay,period < 0,下一次开始执行时间等于triggerTime(-p),为now+(- period),now即上一次执行的结束时间。
14. CompletableFuture用法
从JDK 8开始,在Concurrent包中提供了一个强大的异步编程工具CompletableFuture。在JDK8之前,异步编程可以通过线程池和Future来实现,但功能还不够强大。 示例代码:
CompletableFuture实现了Future接口,所以它也具有Future的特性:调用get()方法会阻塞在那, 直到结果返回。 另外1个线程调用complete方法完成该Future,则所有阻塞在get()方法的线程都将获得返回结果。
14.1 runAsync与supplyAsync
上面的例子是一个空的任务,下面尝试提交一个真的任务,然后等待结果返回。
例1:runAsync(Runnable)
CompletableFuture.runAsync(...)传入的是一个Runnable接口。 例2:supplyAsync(Supplier)
例2和例1的区别在于,例2的任务有返回值。没有返回值的任务,提交的是Runnable,返回的是
CompletableFuture
14.2 thenRun、thenAccept和thenApply
对于 Future,在提交任务之后,只能调用 get()等结果返回;但对于 CompletableFuture,可以在结果上面再加一个callback,当得到结果之后,再接着执行callback。 例1:thenRun(Runnable)
该案例最后不能获取到结果,只会得到一个null。
例2:thenAccept(Consumer)
上述代码在thenAccept中可以获取任务的执行结果,接着进行处理。
例3:thenApply(Function)
三个例子都是在任务执行完成之后,接着执行回调,只是回调的形式不同:
1.thenRun后面跟的是一个无参数、无返回值的方法,即Runnable,所以最终的返回值是CompletableFuture
14.3 thenCompose与thenCombine
例1:thenCompose 在上面的例子中,thenApply接收的是一个Function,但是这个Function的返回值是一个通常的基 本数据类型或一个对象,而不是另外一个 CompletableFuture。如果 Function 的返回值也是一个 CompletableFuture,就会出现嵌套的CompletableFuture。考虑下面的例子:
如果希望返回值是一个非嵌套的CompletableFuture,可以使用thenCompose:
下面是thenCompose方法的接口定义:
CompletableFuture中的实现:
从该方法的定义可以看出,它传入的参数是一个Function类型,并且Function的返回值必须是 CompletionStage的子类,也就是CompletableFuture类型。 例2:thenCombine thenCombine方法的接口定义如下,从传入的参数可以看出,它不同于thenCompose。
第1个参数是一个CompletableFuture类型,第2个参数是一个方法,并且是一个BiFunction,也就 是该方法有2个输入参数,1个返回值。 从该接口的定义可以大致推测,它是要在2个 CompletableFuture 完成之后,把2个 CompletableFuture的返回值传进去,再额外做一些事情。实例如下:
14.4 任意个CompletableFuture的组合
上面的thenCompose和thenCombine只能组合2个CompletableFuture,而接下来的allOf 和 anyOf 可以组合任意多个CompletableFuture。方法接口定义如下所示。
首先,这两个方法都是静态方法,参数是变长的CompletableFuture的集合。其次,allOf和anyOf 的区别,前者是“与”,后者是“或”。
allOf的返回值是CompletableFuture
anyOf 的含义是只要有任意一个 CompletableFuture 结束,就可以做接下来的事情,而无须像 AllOf那样,等待所有的CompletableFuture结束。 但由于每个CompletableFuture的返回值类型都可能不同,任意一个,意味着无法判断是什么类 型,所以anyOf的返回值是CompletableFuture
14.5 四种任务原型
通过上面的例子可以总结出,提交给CompletableFuture执行的任务有四种类型:Runnable、 Consumer、Supplier、Function。下面是这四种任务原型的对比。
四种任务原型 无参数 有参数 无返回值 Runnable接口 对应的提交方法:runAsync,thenRun Consumer接口 对应的提交方法:thenAccept 有返回值 Supplier接口: 对应的提交方法:supplierAsync Function接口 对应的提交方法:thenApply
runAsync 与 supplierAsync 是 CompletableFuture 的静态方法;而 thenAccept、thenAsync、thenApply是CompletableFutre的成员方法。 因为初始的时候没有CompletableFuture对象,也没有参数可传,所以提交的只能是Runnable或者 Supplier,只能是静态方法;
通过静态方法生成CompletableFuture对象之后,便可以链式地提交其他任务了,这个时候就可以 提交Runnable、Consumer、Function,且都是成员方法。
14.6 CompletionStage接口
CompletableFuture不仅实现了Future接口,还实现了CompletableStage接口。
CompletionStage接口定义的正是前面的各种链式方法、组合方法,如下所示。
关于CompletionStage接口,有几个关键点要说明: 1.所有方法的返回值都是CompletionStage类型,也就是它自己。正因为如此,才能实现如下的 链式调用:future1.thenApply(...).thenApply(...).thenCompose(...).thenRun(...)。 2.thenApply接收的是一个有输入参数、返回值的Function。这个Function的输入参数,必须 是?Super T 类型,也就是T或者T的父类型,而T必须是调用thenApplycompletableFuture对象的类型;返回值则必须是?Extends U类型,也就是U或者U的子类型,而U恰好是thenApply的返回值的CompletionStage对应的类型。 其他方法,诸如thenCompose、thenCombine也是类似的原理。
14.7 CompletableFuture内部原理
14.7.1CompletableFuture的构造:ForkJoinPool CompletableFuture中任务的执行依靠ForkJoinPool:
通过上面的代码可以看到,asyncPool是一个static类型,supplierAsync、asyncSupplyStage也都 是static方法。Static方法会返回一个CompletableFuture类型对象,之后就可以链式调用, CompletionStage里面的各个方法。
14.7.2任务类型的适配 ForkJoinPool接受的任务是ForkJoinTask 类型,而我们向CompletableFuture提交的任务是Runnable/Supplier/Consumer/Function 。因此,肯定需要一个适配机制,把这四种类型的任务转换成ForkJoinTask,然后提交给ForkJoinPool,如下图所示:
为了完成这种转换,在CompletableFuture内部定义了一系列的内部类,下图是 CompletableFuture的各种内部类的继承体系。 在 supplyAsync(...)方法内部,会把一个 Supplier 转换成一个 AsyncSupply,然后提交给ForkJoinPool执行; 在runAsync(...)方法内部,会把一个Runnable转换成一个AsyncRun,然后提交给ForkJoinPool执 行; 在 thenRun/thenAccept/thenApply 内部,会分别把 Runnable/Consumer/Function 转换成 UniRun/UniAccept/UniApply对象,然后提交给ForkJoinPool执行; 除此之外,还有两种 CompletableFuture 组合的情况,分为“与”和“或”,所以有对应的Bi和Or类型的Completion类型。
下面的代码分别为 UniRun、UniApply、UniAccept 的定义,可以看到,其内部分别封装了 Runnable、Function、Consumer。
14.7.3任务的链式执行过程分析 下面以CompletableFuture.supplyAsync(...).thenApply(...).thenRun(...)链式代码为例,分析整个执 行过程。 第1步:CompletableFuture future1=CompletableFuture.supplyAsync(...)
在上面的代码中,关键是构造了一个AsyncSupply对象,该对象有三个关键点: 1.它继承自ForkJoinTask,所以能够提交ForkJoinPool来执行。
2.它封装了Supplier f,即它所执行任务的具体内容。 3.该任务的返回值,即CompletableFuture d,也被封装在里面。
ForkJoinPool执行一个ForkJoinTask类型的任务,即AsyncSupply。该任务的输入就是Supply,输 出结果存放在CompletableFuture中。
第2步:CompletableFuture future2=future1.thenApply(...) 第1步的返回值,也就是上面代码中的 CompletableFuture d,紧接着调用其成员方法thenApply:
我们知道,必须等第1步的任务执行完毕,第2步的任务才可以执行。因此,这里提交的任务不可能 立即执行,在此处构建了一个UniApply对象,也就是一个ForkJoinTask类型的任务,这个任务放入了第 1个任务的栈当中。
每一个CompletableFuture对象内部都有一个栈,存储着是后续依赖它的任务,如下面代码所示。 这个栈也就是Treiber Stack,这里的stack存储的就是栈顶指针。
上面的UniApply对象类似于第1步里面的AsyncSupply,它的构造方法传入了4个参数: 1.第1个参数是执行它的ForkJoinPool; 2.第2个参数是输出一个CompletableFuture对象。这个参数,也是thenApply方法的返回值, 用来链式执行下一个任务; 3.第3个参数是其依赖的前置任务,也就是第1步里面提交的任务; 4.第4个参数是输入(也就是一个Function对象)。
UniApply对象被放入了第1步的CompletableFuture的栈中,在第1步的任务执行完成之后,就会从 栈中弹出并执行。如下代码:
ForkJoinPool执行上面的AsyncSupply对象的run()方法,实质就是执行Supplier的get()方法。执行 结果被塞入了 CompletableFuture d 当中,也就是赋值给了 CompletableFuture 内部的Object result 变量。 调用d.postComplete(),也正是在这个方法里面,把第2步压入的UniApply对象弹出来执行,代码 如下所示。
第3步:CompletableFuture future3=future2.thenRun() 第3步和第2步的过程类似,构建了一个 UniRun 对象,这个对象被压入第2步的CompletableFuture所在的栈中。第2步的任务,当执行完成时,从自己的栈中弹出UniRun对象并执 行。
综上所述: 通过supplyAsync/thenApply/thenRun,分别提交了3个任务,每1个任务都有1个返回值对象,也 就是1个CompletableFuture。这3个任务通过2个CompletableFuture完成串联。后1个任务,被放入了 前1个任务的CompletableFuture里面,前1个任务在执行完成时,会从自己的栈中,弹出下1个任务执 行。如此向后传递,完成任务的链式执行。
14.7.4thenApply与thenApplyAsync的区别 在上面的代码中,我们分析了thenApply,还有一个与之对应的方法是thenApplyAsync。这两个方 法调用的是同一个方法,只不过传入的参数不同。
对于上一个任务已经得出结果的情况:
如果e != null表示是thenApplyAsync,需要调用ForkJoinPool的execute方法,该方法:
通过上面的代码可以看到: 1.如果前置任务没有完成,即a.result=null,thenApply和thenApplyAsync都会将当前任务的下 一个任务入栈;然后再出栈执行; 2.只有在当前任务已经完成的情况下,thenApply才会立即执行,不会入栈,再出栈,不会交给ForkJoinPool;thenApplyAsync还是将下一个任务封装为ForkJoinTask,入栈,之后出栈再执 行。 同理,thenRun与thenRunAsync、thenAccept与thenAcceptAsync的区别与此类似。
14.8 任务的网状执行:有向无环图
如果任务只是链式执行,便不需要在每个CompletableFuture里面设1个栈了,用1个指针使所有任 务组成链表即可。 但实际上,任务不只是链式执行,而是网状执行,组成 1 张图。如下图所示,所有任务组成一个有向无环图: 任务一执行完成之后,任务二、任务三可以并行,在代码层面可以写为:future1.thenApply(任务 二),future1.thenApply(任务三); 任务四在任务二执行完成时可开始执行; 任务五要等待任务二、任务三都执行完成,才能开始,这里是AND关系; 任务六在任务三执行完成时可以开始执行; 对于任务七,只要任务四、任务五、任务六中任意一个任务结束,就可以开始执行。 总而言之,任务之间是多对多的关系:1个任务有n个依赖它的后继任务;1个任务也有n个它依赖的 前驱任务。
这样一个有向无环图,用什么样的数据结构表达呢?AND和OR的关系又如何表达呢? 有几个关键点: 1.在每个任务的返回值里面,存储了依赖它的接下来要执行的任务。所以在上图中,任务一的 CompletableFuture的栈中存储了任务二、任务三;任务二的CompletableFuutre中存储了任 务四、任务五;任务三的CompletableFuture中存储了任务五、任务六。即每个任务的 CompletableFuture对象的栈里面,其实存储了该节点的出边对应的任务集合。 2.任务二、任务三的CompletableFuture里面,都存储了任务五,那么任务五是不是会被触发两 次,执行两次呢? 任务五的确会被触发二次,但它会判断任务二、任务三的结果是不是都完成,如果只完成其中 一个,它就不会执行。 3.任务七存在于任务四、任务五、任务六的CompletableFuture的栈里面,因此会被触发三次。 但它只会执行一次,只要其中1个任务执行完成,就可以执行任务七了。 4.正因为有AND和OR两种不同的关系,因此对应BiApply和OrApply两个对象,这两个对象的构 造方法几乎一样,只是在内部执行的时候,一个是AND的逻辑,一个是OR的逻辑。
5.BiApply和OrApply都是二元操作符,也就是说,只能传入二个被依赖的任务。但上面的任务 七同时依赖于任务四、任务五、任务六,这怎么处理呢? 任何一个多元操作,都能被转换为多个二元操作的叠加。如上图所示,假如任务一AND任务二AND任务三 ==> 任务四,那么它可以被转换为右边的形式。新建了一个AND任务,这个AND 任务和任务三再作为参数,构造任务四。OR的关系,与此类似。 此时,thenCombine的内部实现原理也就可以解释了。thenCombine用于任务一、任务二执行完 成,再执行任务三。
14.9 allOf内部的计算图分析
下面以allOf方法为例,看一下有向无环计算图的内部运作过程:
上面的方法是一个递归方法,输入是一个CompletableFuture对象的列表,输出是一个具有AND关 系的复合CompletableFuture对象。 最关键的代码如上面加注释部分所示,因为d要等a,b都执行完成之后才能执行,因此d会被分别压 入a,b所在的栈中。
下图为allOf内部的运作过程。假设allof的参数传入了future1、future2、future3、future4,则对 应四个原始任务。 生成BiRelay1、BiRelay2任务,分别压入future1/future2、future3/future4的栈中。无论future1 或future2完成,都会触发BiRelay1;无论future3或future4完成,都会触发BiRelay2; 生成BiRelay3任务,压入future5/future6的栈中,无论future5或future6完成,都会触发BiRelay3 任务。
BiRelay只是一个中转任务,它本身没有任务代码,只是参照输入的两个future是否完成。如果完 成,就从自己的栈中弹出依赖它的BiRelay任务,然后执行。
第四部分:ForkJoinPool
15. ForkJoinPool用法
ForkJoinPool就是JDK7提供的一种“分治算法”的多线程并行计算框架。Fork意为分叉,Join意为合 并,一分一合,相互配合,形成分治算法。此外,也可以将ForkJoinPool看作一个单机版的Map/Reduce,多个线程并行计算。 相比于ThreadPoolExecutor,ForkJoinPool可以更好地实现计算的负载均衡,提高资源利用率。 假设有5个任务,在ThreadPoolExecutor中有5个线程并行执行,其中一个任务的计算量很大,其余 4个任务的计算量很小,这会导致1个线程很忙,其他4个线程则处于空闲状态。 利用ForkJoinPool,可以把大的任务拆分成很多小任务,然后这些小任务被所有的线程执行,从而 实现任务计算的负载均衡。
例子1:快排
快排有2个步骤: 1.利用数组的第1个元素把数组划分成两半,左边数组里面的元素小于或等于该元素,右边数组 里面的元素比该元素大; 2.对左右的两个子数组分别排序。
左右两个子数组相互独立可以并行计算。利用ForkJoinPool,代码如下:
30 31 32 33 34 35 36 37 38 39 } 40
int i = lo - 1; for (int j = lo; j < hi; j++) { if (array[j] <= x) { i++; swap(array, i, j); } } swap(array, i + 1, hi); return i + 1;
41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 } 66
private void swap(long[] array, int i, int j) { if (i != j) { long temp = array[i]; array[i] = array[j]; array[j] = temp; } }
@Override protected void compute() { if (lo < hi) { // 找到分区的元素下标 int pivot = partition(array, lo, hi); // 将数组分为两部分 SortTask left = new SortTask(array, lo, pivot - 1); SortTask right = new SortTask(array, pivot + 1, hi);
left.fork(); right.fork(); left.join(); right.join(); } }
67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 }
public static void main(String[] args) throws InterruptedException { long[] array = {5, 3, 7, 9, 2, 4, 1, 8, 10}; // 一个任务 ForkJoinTask sort = new SortTask(array); // 一个pool ForkJoinPool pool = new ForkJoinPool(); // ForkJoinPool开启多个线程,同时执行上面的子任务pool.submit(sort); // 结束ForkJoinPool pool.shutdown(); // 等待结束Pool pool.awaitTermination(10, TimeUnit.SECONDS);
System.out.println(Arrays.toString(array)); }
例子2:求1到n个数的和
1 package com.lagou.concurrent.demo; 2
3import java.util.concurrent.ExecutionException;
4import java.util.concurrent.ForkJoinPool;
5import java.util.concurrent.ForkJoinTask;
6import java.util.concurrent.RecursiveTask; 7
8 public class ForkJoinPoolDemo02 { 9
10static class SumTask extends RecursiveTask
54 }
上面的代码用到了 RecursiveAction 和 RecursiveTask 两个类,它们都继承自抽象类 ForkJoinTask,用到了其中关键的接口 fork()、join()。二者的区别是一个有返回值,一个没有返回值。
RecursiveAction/RecursiveTask类继承关系:
在ForkJoinPool中,对应的接口如下:
16. 核心数据结构
与ThreadPoolExector不同的是,除一个全局的任务队列之外,每个线程还有一个自己的局部队 列。
核心数据结构如下所示:
下面看一下这些核心数据结构的构造过程。
1public ForkJoinPool(int parallelism, 2ForkJoinWorkerThreadFactory factory, 3UncaughtExceptionHandler handler, 4boolean asyncMode, 5int corePoolSize, 6int maximumPoolSize, 7int minimumRunnable, 8Predicate<? super ForkJoinPool> saturate, 9long keepAliveTime, 10TimeUnit unit) { 11// check, encode, pack parameters 12if (parallelism <= 0 || parallelism > MAX_CAP || 13maximumPoolSize < parallelism || keepAliveTime <= 0L) 14throw new IllegalArgumentException(); 15if (factory == null) 16throw new NullPointerException(); 17long ms = Math.max(unit.toMillis(keepAliveTime), TIMEOUT_SLOP); 18 19int corep = Math.min(Math.max(corePoolSize, parallelism), MAX_CAP); 20long c = ((((long)(-corep) << TC_SHIFT) & TC_MASK) | 21(((long)(-parallelism) << RC_SHIFT) & RC_MASK)); 22int m = parallelism | (asyncMode ? FIFO : 0); 23int maxSpares = Math.min(maximumPoolSize, MAX_CAP) - parallelism; 24int minAvail = Math.min(Math.max(minimumRunnable, 0), MAX_CAP); 25int b = ((minAvail - parallelism) & SMASK) | (maxSpares << SWIDTH); 26 // 27 int n = (parallelism > 1) ? parallelism - 1 : 1; // at least 2 slots 28 n |= n >>> 1; n |= n >>> 2; n |= n >>> 4; n |= n >>> 8; n |= n >>> 16; 29 n = (n + 1) << 1; // power of two, including space for submission queues 30 31// 工作线程名称前缀 32this.workerNamePrefix = "ForkJoinPool-" + nextPoolId() + "-worker-"; 33// 初始化工作线程数组为n,2的幂次方 34this.workQueues = new WorkQueue[n]; 35// worker线程工厂,有默认值 36this.factory = factory; 37this.ueh = handler; 38this.saturate = saturate; 39this.keepAlive = ms; 40this.bounds = b; 41this.mode = m; 42// ForkJoinPool的状态 43this.ctl = c; 44checkPermission(); 45 }
17. 工作窃取队列
关于上面的全局队列,有一个关键点需要说明:它并非使用BlockingQueue,而是基于一个普通的 数组得以实现。
这个队列又名工作窃取队列,为 ForkJoinPool 的工作窃取算法提供服务。在 ForkJoinPool开篇的注释中,Doug Lea 特别提到了工作窃取队列的实现,其陈述来自如下两篇论文:"Dynamic Circular Work-Stealing Deque" by Chase and Lev,SPAA 2005 与 "Idempotent work stealing" by Michael,Saraswat,and Vechev,PPoPP 2009。读者可以在网上查阅相应论文。
所谓工作窃取算法,是指一个Worker线程在执行完毕自己队列中的任务之后,可以窃取其他线程队 列中的任务来执行,从而实现负载均衡,以防有的线程很空闲,有的线程很忙。这个过程要用到工作窃 取队列。
这个队列只有如下几个操作: 1.Worker线程自己,在队列头部,通过对top指针执行加、减操作,实现入队或出队,这是单线 程的。 2.其他Worker线程,在队列尾部,通过对base进行累加,实现出队操作,也就是窃取,这是多 线程的,需要通过CAS操作。
这个队列,在Dynamic Circular Work-Stealing Deque这篇论文中被称为dynamic-cyclic-array。之所以这样命名,是因为有两个关键点: 1.整个队列是环形的,也就是一个数组实现的RingBuffer。并且base会一直累加,不会减小; top会累加、减小。最后,base、top的值都会大于整个数组的长度,只是计算数组下标的时 候,会取top&(queue.length-1),base&(queue.length-1)。因为queue.length是2的整 数次方,这里也就是对queue.length进行取模操作。 当top-base=queue.length-1 的时候,队列为满,此时需要扩容; 当top=base的时候,队列为空,Worker线程即将进入阻塞状态。
2.当队列满了之后会扩容,所以被称为是动态的。但这就涉及一个棘手的问题:多个线程同时在 读写这个队列,如何实现在不加锁的情况下一边读写、一边扩容呢?
通过分析工作窃取队列的特性,我们会发现:在 base 一端,是多线程访问的,但它们只会使base 变大,也就是使队列中的元素变少。所以队列为满,一定发生在top一端,对top进行累加的时候,这一 端却是单线程的!队列的扩容恰好利用了这个单线程的特性!即在扩容过程中,不可能有其他线程对top 进行修改,只有线程对base进行修改! 下图为工作窃取队列扩容示意图。扩容之后,数组长度变成之前的二倍,但top、base的值是不变 的!通过top、base对新的数组长度取模,仍然可以定位到元素在新数组中的位置。
下面结合WorkQueue扩容的代码进一步分析。
18. ForkJoinPool状态控制
18.1 状态变量ctl解析
类似于ThreadPoolExecutor,在ForkJoinPool中也有一个ctl变量负责表达ForkJoinPool的整个生命 周期和相关的各种状态。不过ctl变量更加复杂,是一个long型变量,代码如下所示。
1
2
3
4
5
6
7
public class ForkJoinPool extends AbstractExecutorService {
// ...
// 线程池状态变量
volatile long ctl;
private static final long SP_MASK = 0xffffffffL; private static final long UC_MASK = ~SP_MASK; private static final int RC_SHIFT = 48;
8 private static final long RC_UNIT = 0x0001L << RC_SHIFT;
9 private static final long RC_MASK = 0xffffL << RC_SHIFT;
10 private static final int TC_SHIFT = 32;
11 private static final long TC_UNIT = 0x0001L << TC_SHIFT;
12 private static final long TC_MASK = 0xffffL << TC_SHIFT;
13 private static final long ADD_WORKER = 0x0001L << (TC_SHIFT + 15); //
14 15 16 sign
// ... }
ctl变量的64个比特位被分成五部分: 1.AC:最高的16个比特位,表示Active线程数-parallelism,parallelism是上面的构造方法传进 去的参数; 2.TC:次高的16个比特位,表示Total线程数-parallelism; 3.ST:1个比特位,如果是1,表示整个ForkJoinPool正在关闭; 4.EC:15个比特位,表示阻塞栈的栈顶线程的wait count(关于什么是wait count,接下来解释); 5.ID:16个比特位,表示阻塞栈的栈顶线程对应的id。
18.2 阻塞栈Treiber Stack
什么叫阻塞栈呢? 要实现多个线程的阻塞、唤醒,除了park/unpark这一对操作原语,还需要一个无锁链表实现的阻 塞队列,把所有阻塞的线程串在一起。
在ForkJoinPool中,没有使用阻塞队列,而是使用了阻塞栈。把所有空闲的Worker线程放在一个栈 里面,这个栈同样通过链表来实现,名为Treiber Stack。前面讲解Phaser的实现原理的时候,也用过这个数据结构。
下图为所有阻塞的Worker线程组成的Treiber Stack。
首先,WorkQueue有一个id变量,记录了自己在WorkQueue[]数组中的下标位置,id变量就相当于 每个WorkQueue或ForkJoinWorkerThread对象的地址;
其次,ForkJoinWorkerThread还有一个stackPred变量,记录了前一个阻塞线程的id,这个 stackPred变量就相当于链表的next指针,把所有的阻塞线程串联在一起,组成一个Treiber Stack。
最后,ctl变量的最低16位,记录了栈的栈顶线程的id;中间的15位,记录了栈顶线程被阻塞的次 数,也称为wait count。
18.3 ctl变量的初始值
构造方法中,有如下的代码:
因为在初始的时候,ForkJoinPool 中的线程个数为 0,所以 AC=0-parallelism,TC=0- parallelism。这意味着只有高32位的AC、TC 两个部分填充了值,低32位都是0填充。
18.4 ForkJoinWorkerThread状态与个数分析
在ThreadPoolExecutor中,有corePoolSize和maxmiumPoolSize 两个参数联合控制总的线程数, 而在ForkJoinPool中只传入了一个parallelism参数,且这个参数并不是实际的线程数。那么, ForkJoinPool在实际的运行过程中,线程数究竟是由哪些因素决定的呢? 要回答这个问题,先得明白ForkJoinPool中的线程都可能有哪几种状态?可能的状态有三种: 1.空闲状态(放在Treiber Stack里面)。 2.活跃状态(正在执行某个ForkJoinTask,未阻塞)。 3.阻塞状态(正在执行某个ForkJoinTask,但阻塞了,于是调用join,等待另外一个任务的结果 返回)。
ctl变量很好地反映出了三种状态: 高32位:u=(int) (ctl >>> 32),然后u又拆分成tc、ac 两个16位; 低32位:c=(int) ctl。
1.c>0,说明Treiber Stack不为空,有空闲线程;c=0,说明没有空闲线程; 2.ac>0,说明有活跃线程;ac<=0,说明没有空闲线程,并且还未超出parallelism; 3.tc>0,说明总线程数 >parallelism。
在提交任务的时候:
在通知工作线程的时候,需要判断ctl的状态,如果没有闲置的线程,则开启新线程:
19. Worker线程的阻塞-唤醒机制
ForkerJoinPool 没有使用 BlockingQueue,也就不利用其阻塞/唤醒机制,而是利用了park/unpark 原语,并自行实现了Treiber Stack。 下面进行详细分析ForkerJoinPool,在阻塞和唤醒的时候,分别是如何入栈的。
19.1 阻塞–入栈
当一个线程窃取不到任何任务,也就是处于空闲状态时就会阻塞入栈。
20 21 22 23 24 25 26 }
do { w.stackPred = (int)(c = ctl); // ForkJoinPool中status表示运行中的线程的,数字减一,因为入队列了。nc = ((c - RC_UNIT) & UC_MASK) | np; // CAS操作,自旋,直到操作成功 } while (!CTL.weakCompareAndSet(this, c, nc));
27else { // already queued 28int pred = w.stackPred; 29Thread.interrupted(); // clear before park 30w.source = DORMANT; // enable signal 31long c = ctl; 32int md = mode, rc = (md & SMASK) + (int)(c >> RC_SHIFT); 33// 如果ForkJoinPool停止,则break,跳出循环 34if (md < 0) 35break; 36// 优雅关闭 37else if (rc <= 0 && (md & SHUTDOWN) != 0 && 38tryTerminate(false, false)) 39break; 40else if (rc <= 0 && pred != 0 && phase == (int)c) { 41long nc = (UC_MASK & (c - TC_UNIT)) | (SP_MASK & pred); 42long d = keepAlive + System.currentTimeMillis(); 43// 线程阻塞,计时等待 44LockSupport.parkUntil(this, d); 45 // 46if (ctl == c && // drop on timeout if all idle 47d - System.currentTimeMillis() <= TIMEOUT_SLOP &&
48 CTL.compareAndSet(this, c, nc)) {
49 // 不再扫描,需要入队列
50 w.phase = QUIET;
51 break;
52 }
53 }
54 // phase为1,表示加锁,phase为负数表示入队列
55 else if (w.phase < 0)
56 // 如果phase小于0,表示阻塞,排队中
57 LockSupport.park(this);
58 w.source = 0;
59 }
60 }
61 }
19.2 唤醒–出栈
在新的任务到来之后,空闲的线程被唤醒,其核心逻辑在signalWork方法里面。
20. 任务的提交过程分析
在明白了工作窃取队列、ctl变量的各种状态、Worker的各种状态,以及线程阻塞—唤醒机制之后, 接下来综合这些知识,详细分析任务的提交和执行过程。
关于任务的提交,ForkJoinPool最外层的接口如下所示。
如何区分一个任务是内部任务,还是外部任务呢? 可以通过调用该方法的线程类型判断。 如果线程类型是ForkJoinWorkerThread,说明是线程池内部的某个线程在调用该方法,则把该任务 放入该线程的局部队列; 否则,是外部线程在调用该方法,则将该任务加入全局队列。
20.1 内部提交任务push
内部提交任务,即上面的q.push(task),会放入该线程的工作窃取队列中,代码如下所示。
由于工作窃取队列的特性,操作是单线程的,所以此处不需要执行CAS操作。
20.2 外部提交任务
13if ((md & SHUTDOWN) != 0 || ws == null || (n = ws.length) <= 0) 14throw new RejectedExecutionException(); 15 16// 如果随机数计算的workQueues索引处的元素为null,则添加队列 17// 即提交任务的时候,是随机向workQueue中添加workQueue,负载均衡的考虑。 18else if ((q = ws[(n - 1) & r & SQMASK]) == null) { // add queue 19// 计算新workQueue对象的id值 20int qid = (r | QUIET) & ~(FIFO | OWNED); 21// worker线程名称前缀 22Object lock = workerNamePrefix; 23// 创建任务数组 24ForkJoinTask<?>[] qa = 25new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY]; 26// 创建WorkQueue,将当前线程作为 27q = new WorkQueue(this, null); 28// 将任务数组赋值给workQueue 29q.array = qa; 30// 设置workQueue的id值 31q.id = qid; 32// 由于是通过客户端线程添加的workQueue,没有前置workQueue 33// 内部提交任务有源workQueue,表示子任务 34q.source = QUIET; 35if (lock != null) { // unless disabled, lock pool to install 36synchronized (lock) { 37WorkQueue[] vs; int i, vn; 38// 如果workQueues数组不是null,其中有元素, 39// 并且qid对应的workQueues中的元素为null,则赋值 40// 因为有可能其他线程将qid对应的workQueues处的元素设置了, 41// 所以需要加锁,并判断元素是否为null 42if ((vs = workQueues) != null && (vn = vs.length) > 0 && 43vs[i = qid & (vn - 1) & SQMASK] == null) 44 // 45 vs[i] = q; 46 } 47 }
48 }
49 // CAS操作,使用随机数
50 else if (!q.tryLockPhase()) // move if busy
51 r = ThreadLocalRandom.advanceProbe(r);
52 else {
53 // 如果任务添加成功,通知线程池调度,执行。
54 if (q.lockedPush(task))
55 signalWork();
56 return;
57 }
58 }
59 }
lockedPush(task)方法的实现:
外部多个线程会调用该方法,所以要加锁,入队列和扩容的逻辑和线程内部的队列基本相同。最 后,调用signalWork(),通知一个空闲线程来取。
21. 工作窃取算法:任务的执行过程分析
全局队列有任务,局部队列也有任务,每一个Worker线程都会不间断地扫描这些队列,窃取任务来 执行。下面从Worker线程的run方法开始分析:
run()方法调用的是所在ForkJoinPool的runWorker方法,如下所示。
1final void runWorker(WorkQueue w) { 2int r = (w.id ^ ThreadLocalRandom.nextSecondarySeed()) | FIFO; // rng 3w.array = new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY]; // initialize 4 for (;;) { 5int phase; 6if (scan(w, r)) { // scan until apparently empty 7 r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // move (xorshift) 8 } 9 else if ((phase = w.phase) >= 0) { // enqueue, then rescan 10long np = (w.phase = (phase + SS_SEQ) | UNSIGNALLED) & SP_MASK; 11long c, nc; 12do { 13w.stackPred = (int)(c = ctl); 14nc = ((c - RC_UNIT) & UC_MASK) | np; 15} while (!CTL.weakCompareAndSet(this, c, nc)); 16 } 17else { // already queued 18int pred = w.stackPred; 19Thread.interrupted(); // clear before park 20w.source = DORMANT; // enable signal 21long c = ctl; 22int md = mode, rc = (md & SMASK) + (int)(c >> RC_SHIFT); 23if (md < 0) // terminating 24break; 25else if (rc <= 0 && (md & SHUTDOWN) != 0 && 26tryTerminate(false, false)) 27break; // quiescent shutdown 28else if (rc <= 0 && pred != 0 && phase == (int)c) { 29long nc = (UC_MASK & (c - TC_UNIT)) | (SP_MASK & pred); 30long d = keepAlive + System.currentTimeMillis(); 31LockSupport.parkUntil(this, d); 32if (ctl == c && // drop on timeout if all idle 33d - System.currentTimeMillis() <= TIMEOUT_SLOP && 34CTL.compareAndSet(this, c, nc)) { 35w.phase = QUIET; 36break; 37 } 38 } 39else if (w.phase < 0) 40LockSupport.park(this); // OK if spuriously woken 41w.source = 0; // disable signal 42 } 43 } 44 }
下面详细看扫描过程scan(w, a)。
22. ForkJoinTask的fork/join
如果局部队列、全局中的任务全部是相互独立的,就很简单了。但问题是,对于分治算法来说,分 解出来的一个个任务并不是独立的,而是相互依赖,一个任务的完成要依赖另一个前置任务的完成。 这种依赖关系是通过ForkJoinTask中的join()来体现的。且看前面的代码:
线程在执行当前ForkJoinTask的时候,产生了left、right 两个子Task。 fork是指把这两个子Task放入队列里面;
join则是要等待2个子Task完成。 而子Task在执行过程中,会再次产生两个子Task。如此层层嵌套,类似于递归调用,直到最底层的 Task计算完成,再一级级返回。
22.1 fork
fork()的代码很简单,就是把自己放入当前线程所在的局部队列中。如果是外部线程调用fork方法,则直接将任务添加到共享队列中。
22.2 join的嵌套
1.join的层层嵌套阻塞原理 join会导致线程的层层嵌套阻塞,如图所示:
线程1在执行 ForkJoinTask1,在执行过程中调用了 forkJoinTask2.join(),所以要等ForkJoinTask2 完成,线程1才能返回; 线程2在执行ForkJoinTask2,但由于调用了forkJoinTask3.join(),只有等ForkJoinTask3完成后,线 程2才能返回; 线程3在执行ForkJoinTask3。
结果是:线程3首先执行完,然后线程2才能执行完,最后线程1再执行完。所有的任务其实组成一 个有向无环图DAG。如果线程3调用了forkJoinTask1.join(),那么会形成环,造成死锁。
那么,这种层次依赖、层次通知的 DAG,在 ForkJoinTask 内部是如何实现的呢?站在ForkJoinTask的角度来看,每个ForkJoinTask,都可能有多个线程在等待它完成,有1个线程在执行它。 所以每个ForkJoinTask就是一个同步对象,线程在调用join()的时候,阻塞在这个同步对象上面,执行完 成之后,再通过这个同步对象通知所有等待的线程。
利用synchronized关键字和Java原生的wait()/notify()机制,实现了线程的等待-唤醒机制。调用join()的这些线程,内部其实是调用ForkJoinTask这个对象的wait();执行该任务的Worker线程,在任务 执行完毕之后,顺便调用notifyAll()。
2.ForkJoinTask的状态解析
要实现fork()/join()的这种线程间的同步,对应的ForkJoinTask一定是有各种状态的,这个状态变量 是实现fork/join的基础。
1
2
3
4
5
public abstract class ForkJoinTask
初始时,status=0。共有五种状态,可以分为两大类: 1.未完成:status>=0。 2.已完成:status<0。 所以,通过判断是status>=0,还是status<0,就可知道任务是否完成,进而决定调用join()的线 程是否需要被阻塞。
3.join的详细实现
下面看一下代码的详细实现。
getRawResult()是ForkJoinTask中的一个模板方法,分别被RecursiveAction和RecursiveTask实 现,前者没有返回值,所以返回null,后者返回一个类型为V的result变量。
阻塞主要发生在上面的doJoin()方法里面。在dojoin()里调用t.join()的线程会阻塞,然后等待任务t执 行完成,再唤醒该阻塞线程,doJoin()返回。 注意:当 doJoin()返回的时候,就是该任务执行完成的时候,doJoin()的返回值就是任务的完成状态,也就是上面的几种状态。
上面的返回值可读性比较差,变形之后:
先看一下externalAwaitDone(),即外部线程的阻塞过程,相对简单。
内部Worker线程的阻塞,即上面的wt.pool.awaitJoin(w, this, 0L),相比外部线程的阻塞要做更多工作。它现不在ForkJoinTask里面,而是在ForkJoinWorkerThread里面。
1final int awaitJoin(WorkQueue w, ForkJoinTask<?> task, long deadline) { 2int s = 0; 3int seed = ThreadLocalRandom.nextSecondarySeed(); 4if (w != null && task != null && 5(!(task instanceof CountedCompleter) || 6(s = w.helpCC((CountedCompleter<?>)task, 0, false)) >= 0)) { 7// 尝试执行该任务 8w.tryRemoveAndExec(task); 9int src = w.source, id = w.id; 10 int r = (seed >>> 16) | 1, step = (seed & ~1) | 2; 11s = task.status; 12while (s >= 0) { 13WorkQueue[] ws; 14int n = (ws = workQueues) == null ? 0 : ws.length, m = n - 1; 15while (n > 0) { 16WorkQueue q; int b; 17if ((q = ws[r & m]) != null && q.source == id && 18q.top != (b = q.base)) { 19ForkJoinTask<?>[] a; int cap, k; 20int qid = q.id; 21if ((a = q.array) != null && (cap = a.length) > 0) { 22ForkJoinTask<?> t = (ForkJoinTask<?>) 23QA.getAcquire(a, k = (cap - 1) & b); 24if (q.source == id && q.base == b++ && 25t != null && QA.compareAndSet(a, k, t, null)) { 26q.base = b; 27w.source = qid; 28// 执行该任务 29t.doExec(); 30w.source = src; 31 } 32 } 33 break; 34 } 35else { 36r += step; 37 --n; 38 } 39 } 40// 如果任务的status < 0,任务执行完成,则退出循环,返回s的值 41if ((s = task.status) < 0) 42break; 43else if (n == 0) { // empty scan 44long ms, ns; int block; 45if (deadline == 0L) 46ms = 0L; // untimed 47else if ((ns = deadline - System.nanoTime()) <= 0L) 48break; // timeout 49else if ((ms = TimeUnit.NANOSECONDS.toMillis(ns)) <= 0L) 50ms = 1L; // avoid 0 for timed wait 51if ((block = tryCompensate(w)) != 0) { 52task.internalWait(ms);
上面的方法有个关键点:for里面是死循环,并且只有一个返回点,即只有在task.status<0,任务 完成之后才可能返回。否则会不断自旋;若自旋之后还不行,就会调用task.internalWait(ms);阻塞。 task.internalWait(ms);的代码如下。
4.join的唤醒 调用t.join()之后,线程会被阻塞。接下来看另外一个线程在任务t执行完毕后如何唤醒阻塞的线程。
任务的执行发生在doExec()方法里面,任务执行完成后,调用一个setDone()通知所有等待的线程。 这里也做了两件事: 1.把status置为完成状态。 2.如果s != 0,即 s = SIGNAL,说明有线程正在等待这个任务执行完成。调用Java原生的notifyAll()通知所有线程。如果s = 0,说明没有线程等待这个任务,不需要通知。
23. ForkJoinPool的优雅关闭
同ThreadPoolExecutor一样,ForkJoinPool的关闭也不可能是“瞬时的”,而是需要一个平滑的过渡 过程。
23.1 工作线程的退出
对于一个Worker线程来说,它会在一个for循环里面不断轮询队列中的任务,如果有任务,则执 行,处在活跃状态;如果没有任务,则进入空闲等待状态。 这个线程如何退出呢?
1 /* 2 工作线程的顶级循环,通过ForkJoinWorkerThread.run调用 3 */ 4final void runWorker(WorkQueue w) { 5int r = (w.id ^ ThreadLocalRandom.nextSecondarySeed()) | FIFO; // rng 6w.array = new ForkJoinTask<?>[INITIAL_QUEUE_CAPACITY]; // 初始化任务数组。 7 for (;;) { 8int phase; 9if (scan(w, r)) { // scan until apparently empty 10 r ^= r << 13; r ^= r >>> 17; r ^= r << 5; // move (xorshift) 11 } 12else if ((phase = w.phase) >= 0) { // enqueue, then rescan 13long np = (w.phase = (phase + SS_SEQ) | UNSIGNALLED) & SP_MASK; 14long c, nc; 15do { 16w.stackPred = (int)(c = ctl); 17nc = ((c - RC_UNIT) & UC_MASK) | np; 18} while (!CTL.weakCompareAndSet(this, c, nc)); 19 } 20else { // already queued 21int pred = w.stackPred; 22Thread.interrupted(); // clear before park 23w.source = DORMANT; // enable signal 24long c = ctl; 25int md = mode, rc = (md & SMASK) + (int)(c >> RC_SHIFT);
(int) (c = ctl) < 0,即低32位的最高位为1,说明线程池已经进入了关闭状态。但线程池进入关闭状态,不代表所有的线程都会立马关闭。
23.2 shutdown()与shutdownNow()的区别
二者的代码基本相同,都是调用tryTerminate(boolean, boolean)方法,其中一个传入的是false, 另一个传入的是true。tryTerminate意为试图关闭ForkJoinPool,并不保证一定可以关闭成功:
9 10 } 11
MODE.compareAndSet(this, md, md | SHUTDOWN);
12while (((md = mode) & STOP) == 0) { // try to initiate termination 13if (!now) { // check if quiescent & empty 14for (long oldSum = 0L;;) { // repeat until stable 15boolean running = false; 16long checkSum = ctl; 17WorkQueue[] ws = workQueues; 18if ((md & SMASK) + (int)(checkSum >> RC_SHIFT) > 0) 19// 还有正在运行的线程 20running = true; 21else if (ws != null) { 22WorkQueue w; 23for (int i = 0; i < ws.length; ++i) { 24if ((w = ws[i]) != null) { 25int s = w.source, p = w.phase; 26int d = w.id, b = w.base; 27if (b != w.top || 28 ((d & 1) == 1 && (s >= 0 || p >= 0))) { 29running = true; 30// 还正在运行 31break; 32 } 33 checkSum += (((long)s << 48) + ((long)p << 32) + 34 ((long)b << 16) + (long)d); 35 } 36 } 37 } 38if (((md = mode) & STOP) != 0) 39break; // already triggered 40else if (running) 41return false; 42else if (workQueues == ws && oldSum == (oldSum = checkSum)) 43break; 44 } 45 } 46if ((md & STOP) == 0) 47// 如果需要立即停止,同时md没有设置为STOP,则设置为STOP 48MODE.compareAndSet(this, md, md | STOP); 49 } 50 51// 如果mode还没有设置为TERMINATED,则进行循环 52while (((md = mode) & TERMINATED) == 0) { // help terminate others 53for (long oldSum = 0L;;) { // repeat until stable 54WorkQueue[] ws; WorkQueue w; 55long checkSum = ctl; 56if ((ws = workQueues) != null) { 57for (int i = 0; i < ws.length; ++i) { 58if ((w = ws[i]) != null) { 59ForkJoinWorkerThread wt = w.owner; 60// 清空任务队列 61w.cancelAll(); 62if (wt != null) { 63try { 64// 中断join或park的线程 65wt.interrupt(); 66} catch (Throwable ignore) {
总结:shutdown()只拒绝新提交的任务;shutdownNow()会取消现有的全局队列和局部队列中的 任务,同时唤醒所有空闲的线程,让这些线程自动退出。
第五部分:多线程设计模式
24. Single Threaded Execution模式
所谓Single Threaded Execution模式,指的是“以一个线程执行”。该模式用于设置限制,以确保同一时间只能让一个线程执行处理。 Single Threaded Execution有时也称为临界区(critical section)或临界域(critical region)。Single Threaded Execution名称侧重于执行处理的线程,临界区或临界域侧重于执行范围。
示例程序
运行效果:
上述代码之所以递增异常,是因为showNumber方法是一个临界区,其中对数字加一,但又不能保 证原子性,在多线程执行的时候,就会出现问题。 线程安全的NumberResource类:
29 }
30 // 增加计数
31 printIndex++;
32 }
33 }
34
Single Threaded Execution模式总结 1.SharedResource(共享资源) Single Threaded Execution模式中出现了一个发挥SharedResource(共享资源)作用的类。在示例程序中,由NumberResource类扮演SharedResource角色。 SharedResource角色是可以被多个线程访问的类,包含很多方法,但这些方法主要分为如下两 类: safeMethod: 多 个 线 程 同 时 调 用 也 不 会 发 生 问 题 的 方 法 。 unsafeMethod:多个线程同时访问会发生问题,因此必须加以保护的方法。 safeMethod,无需考虑。 对于unsafeMethod,在被多个线程同时执行时,实例状态有可能发生分歧。这时就需要保护该方 法,使其不被多个线程同时访问。 Single Threaded Execution模式会保护unsafeMethod,使其同时只能由一个线程访问。java则是通过unsafeMethod声明为synchronized方法来进行保护。 我们将只允许单个线程执行的程序范围称为临界区。
Single Threaded Execution类图
何时使用Single Threaded Execution模式 1.多线程时 在单线程程序中使用synchronized关键字并不会破坏程序的安全性,但是调用synchronized方法要 比调用一般方法花费时间,稍微降低程序性能。 2.多个线程访问时 当SharedResource角色的实例有可能被多个线程同时访问时,就需要使用Single Threaded Execution模式。 即便是多线程程序,如果所有线程都是完全独立操作的,也无需使用Single Threaded Execution模式。这种状态称为线程互不干涉。 在某些处理多个线程的框架中,有时线程的独立性是由框架控制的。此时,框架的使用者就无需考 虑是否使用Single Threaded Execution模式。 3.状态有可能变化时 之所以需要使用Single Threaded Execution模式,是因为SharedResource角色的状态会发生变化。 如果在创建实例后,实例的状态再也不发生变化,就无需使用Single Threaded Execution模式。 4.需要确保安全性时 只有在需要确保安全性时,才需要使用Single Threaded Execution模式。 Java的集合类大多数都是非线程安全的。这是为了在不需要考虑安全性的时候提高程序运行速度。 用户在使用类时,需要考虑自己要用的类是否时线程安全的。
死锁 使用Single Threaded Execution模式时,存在发生死锁的危险。 死锁是指两个线程分别持有锁,并相互等待对方释放锁的现象。发生死锁的线程都无法再继续运 行,程序卡死。
两个人吃饭,都需要刀和叉,但刀叉又只有一套。某时刻,其中一个人拿了刀,另一个拿了叉,而 且两人都在等待对方让出自己需要的叉或刀。这种情形下,两个人都只能一直等待下去,这就是发生了 死锁。
在Single Threaded Execution模式中,满足下列条件时,会发生死锁: 存在多个SharedResource角色 线程在持有某个SharedResource角色锁的同时,还想获取其他SharedResource角色的锁 获取SharedResource角色的锁的顺序不固定(SharedResource角色是对称的)
临界区的大小和性能 一般情况下,Single Threaded Execution模式会降低程序性能: 1.获取锁花费时间 进入synchronized方法时,线程需要获取对象的锁,该处理会花费时间。 如果SharedResource角色的数量减少了,那么要获取的锁的数量也会相应地减少,从而就能够抑 制性能的下降了。 2.线程冲突引起的等待 当线程执行临界区内的处理时,其他想要进入临界区的线程会阻塞。这种状况称为线程冲突。发生 冲突时,程序的整体性能会随着线程等待时间的增加而下降。
25. Immutable模式
Immutable就是不变的、不发生改变。Immutable模式中存在着确保实例状态不发生改变的类。在 访问这些实例时不需要执行耗时的互斥处理。如果能用好该模式,就可以提高程序性能。 如String就是一个不可变类,immutable的。
示例程序
6 new UserThread(user).start();
7 new UserThread(user).start();
8 new UserThread(user).start();
9 new UserThread(user).start();
10 new UserThread(user).start();
11 }
12 }
执行效果:
类图
在Single Threaded Execution模式,将修改或引用实例状态的地方设置为临界区,该区只能由一个线程执行。对于本案例的User类,实例的状态绝对不会发生改变,即使多个线程同时对该实例执行处 理,实例也不会出错,因为实例的状态不变。如此也无需使用synchronized关键字来保护实例。
Immutable模式中的角色 1.Immutable Immutable角色是一个类,该角色中的字段值不可修改,也不存在修改字段内容的方法。无需对Immutable角色应用Single Threaded Execution模式。无需使用synchronized关键字。就是本案例的User类。
何时使用Immutable模式 1.创建实例后,状态不再发生改变 必须是实例创建后,状态不再发生变化的。实例的状态由字段的值决定。即使字段是final的且不存 在setter,也有可能不是不可变的。因为字段引用的实例有可能发生变化。 2.实例是共享的,且被频繁访问时 Immutable模式的优点是不需要使用synchronized关键字进行保护。意味着在不失去安全性和生存 性的前提下提高性能。当实例被多个线程共享,且有可能被频繁访问时,Immutable模式优点明显。
注意: StringBuffer类表示字符串的可变类,String类表示字符串的不可变类。String实例表示的字符串不 可以修改,执行操作的方法都不是synchronized修饰的,引用速度更快。 如果需要频繁修改字符串内容,则使用StringBuffer;如果不需要修改字符串内容,只是引用内 容,则使用String。
JDK中的不可变模式 java.lang.String java.math.BigInteger java.math.Decimal java.util.regex.Pattern java.lang.Boolean java.lang.Byte java.lang.Character java.lang.Double java.lang.Float java.lang.Integer java.lang.Long java.lang.Short java.lang.Void
26. Guarded Suspension模式
Guarded表示被守护、被保卫、被保护。Suspension表示暂停。如果执行现在的处理会造成问题, 就让执行处理的线程进行等待——这就是Guarded Suspension模式。 Guarded Suspension模式通过让线程等待来保证实例的安全型。Guarded Suspension也称为guarded wait、spin lock等名称。
示例程序:
执行效果:
应用保护条件进行保护:
上图中,getRequest方法执行的逻辑是从queue中取出一个Request实例,即 queue.remove() , 但是要获取Request实例,必须满足条件: queue.peek() != null 。该条件就是Guarded Suspension模式的守护条件(guard condition)。 当线程执行到while语句时: 若守护条件成立,线程不进入while语句块,直接执行queue.remove()方法,线程不会等待。 若守护条件不成立,线程进入while语句块,执行wait,开始等待。
若守护条件不成立,则线程等待。等待什么?等待notifyAll()唤醒该线程。 守护条件阻止了线程继续向前执行,除非实例状态发生改变,守护条件成立,被另一个线程唤醒。 该类中的synchronized关键字保护的是queue字段,getRequest方法的synchronized保护该方法 只能由一个线程执行。
线程执行this.wait之后,进入this的等待队列,并释放持有的this锁。 notify、notifyAll或interrupt会让线程退出等待队列,实际继续执行之前还必须再次获取this的锁线 程才可以继续执行。
时序图
Guarded Suspension模式中的角色 GuardedObject(被保护的对象) GuardedObject角色是一个持有被保护(guardedMethod)的方法的类。当线程执行guardedMethod方法时,若守护条件成立,立即执行;当守护条件不成立,等待。守护条件随着GuardedObject角色的状态不同而变。 除了guardedMethod之外,GuardedObject角色也可以持有其他改变实例状态 (stateChangingMethod)的方法。 java中,guardedMethod通过while语句和wait方法来实现,stateChangingMethod通过notify/notifyAll方法实现。 在本案例中,RequestQueue为GuardedObject,getRequest方法为guardedMethod, putRequest为stateChangingMethod。
可以将Guarded Suspension理解为多线程版本的if。
LinkedBlockingQueue 可以使用LinkedBlockingQueue替代RequestQueue。
类图
27. Balking模式
所谓Balk,就是停止并返回的意思。 Balking模式与Guarded Suspension模式一样,也存在守护条件。在Balking模式中,如果守护条件不成立,则立即中断处理。而Guarded Suspension模式一直等待直到可以运行。
示例程序 两个线程,一个是修改线程,修改之后,等待随机时长,保存文件内容。另一个是保存线程,固定时长进行文件内容的保存。 如果文件需要保存,则执行保存动作 如果文件不需要保存,则不执行保存动作。
执行效果:
Balking模式中的角色 GuardedObject(受保护对象) GuardedObject角色是一个拥有被保护的方法(guardedMethod)的类。当线程执行guardedMethod时,若保护条件成立,则执行实际的处理,若不成立,则不执行实际的处理,直接返 回。 保护条件的成立与否随着GuardedObject角色状态的改变而变动。 除了guardedMethod之外,GuardedObject角色还有可能有其他改变状态的方法 (stateChangingMethod)。
在此案例中,Data类对应于GuardedObject,save方法对应guardedMethod,change方法对应 stateChangingMethod方法。 保护条件是changed字段为true。
类图
何时使用Balking模式 不需要执行时 在此示例程序中,content字段的内容如果没有修改,就将save方法balk。之所以要balk,是因为content已经写文件了,无需再写了。如果并不需要执行,就可以使用Balking模式。此时可以提高程序 性能。 不需要等待守护条件成立时 Balking模式的特点就是不等待。若条件成立,就执行,若不成立,就不执行,立即进入下一个操 作。 守护条件仅在第一次成立时 当“守护条件仅在第一次成立”时,可以使用Balking模式。 比如各种类的初始化操作,检查一次是否初始化了,如果初始化了,就不用执行了。如果没有初始 化,则进行初始化。
balk结果的表示 1.忽略balk 最简单的方式就是不通知调用端“发生了balk”。示例程序采用的就是这种方式。 2.通过返回值表示balk 通过boolean值表示balk。若返回true,表示未发生balk,需要执行并执行了处理。若false,则表 示发生了balk,处理已执行,不再需要执行。 有时也会使用null来表示“发生了balk”。 3.通过异常表示balk 有时也通过异常表示“发生了balk”。即,当balk时,程序并不从方法return,而是抛异常。
Balking和Guarded Suspension模式之间 介于“直接balk并返回”和“等待到守护条件成立为止“这两种极端之间的还有一种”在守护条件成立之 前等待一段时间“。在守护条件成立之前等待一段时间,如果到时条件还未成立,则直接balk。 这种操作称为计时守护(guarded timed)或超时(timeout)。
java.util.concurrent中的超时
1.通过异常通知超时 当发生超时抛出异常时,不适合使用返回值表示超时,需要使用 java.util.concurrent.TimeoutException异常。 如: java.util.concurrent.Future的get方法; java.util.concurrent.Exchanger的exchange方法; java.util.concurrent.Cyclicarrier的await方法 java.util.concurrent.CountDownLatch的await方法。
2.通过返回值通知超时 当执行多次try时,则不使用异常,而使用返回值表示超时。如: java.util.concurrent.BlockingQueue接口,当offer方法的返回值为false,或poll方法的返回值为null,表示发生了超时。 java.util.concurrent.Semaphore类,当tryAcquire方法的返回值为false时,表示发生了超时。java.util.concurrent.locks.Lock接口,当tryLock方法的返回值为false时,表示发生了超时。
28. Producer-Consumer模式
生产者安全地将数据交给消费者。 当生产者和消费者以不同的线程运行时,两者之间的处理速度差异会有问题。生产者消费者模式用于消除线程间处理速度的差异带来的问题。 在该模式中,生产者和消费者都有多个,当生产者和消费者只有一个时,我们称为管道(Pipe)模 式。
示例程序
执行效果:
关于put方法
put方法会抛出InterruptedException异常。如果抛出,可以理解为”该操作已取消“。put方法使用了Guarded Suspension模式。 tail和count的更新采取buffer环的形式。notifyAll方法唤醒正在等待馒头的线程来吃。
关于take方法 take方法会抛出InterruptedException异常,表示该操作已取消。take方法采用了Guarded Suspension模式。 head和count的更新采用了buffer环的形式。 notifyAll唤醒等待的厨子线程开始蒸馒头。
时序图:
Producer-Consumer模式中的角色 1.Data Data角色由Producer角色生成,供Consumer角色使用。在本案例中,String类的馒头对应于Data 角色。 2.Producer Producer角色生成Data角色,并将其传递给Channel角色。本案例中,CookerThread对应于Producer角色。 3.Consumer
Consumer角色从Channel角色获取Data角色并使用。本案例中,EaterThread对应于Consumer角 色。 4.Channel角色 Channel角色管理从Producer角色获取的Data角色,还负责响应Consumer角色的请求,传递Data 角色。为了安全,Channel角色会对Producer角色和Consumer角色进行互斥处理。 当producer角色将Data角色传递给Channel角色时,如果Channel角色状态不能接收Data角色,则 Producer角色将一直等待,直到Channel可以接收Data角色为止。 当Consumer角色从Channel角色获取Data角色时,如果Channel角色状态没有可以传递的Data角 色,则Consumer角色将一直等待,直到Channel角色状态转变为可以传递Data角色为止。 当存在多个Producer角色和Consumer角色时,Channel角色需要对它们做互斥处理。
类图:
守护安全性的Channel角色(可复用) 在生产者消费者模型中,承担安全守护责任的是Channel角色。Channel角色执行线程间的互斥处 理,确保Producer角色正确地将Data角色传递给Consumer角色。 不要直接传递 Consumer角色想要获取Data角色,通常是因为想使用这些Data角色来执行某些处理。如果Producer角色直接调用Consumer的方法,执行处理的就不是Consumer的线程,而是Producer角色的 线程了。这样一来,异步处理变同步处理,会发生不同Data间的延迟,降低程序的性能。 传递Data角色的顺序 1.队列——先生产先消费 2.栈——先生产后消费 3.优先队列——”优先“的先消费
Channel意义 线程的协调要考虑”放在中间的东西“ 线程的互斥要考虑”应该保护的东西“ 为了让线程协调运行,必须执行互斥处理,以防止共享的内容被破坏。线程的互斥处理时为了线程 的协调运行而执行的。
JUC包和Producer-Consumer模式 JUC中提供了BlockingQueue接口及其实现类,相当于Producer-Consumer模式中的Channel角 色。
BlockingQueue接口——阻塞队列ArrayBlockingQueue——基于数组的BlockingQueue LinkedBlockingQueue——基于链表的BlockingQueue PriorityBlockingQueue——带有优先级的BlockingQueue DelayQueue——一定时间之后才可以take的BlockingQueue SynchronousQueue——直接传递的BlockingQueue ConcurrentLinkedQueue——元素个数没有最大限制的线程安全队列
29. Read-Write Lock模式
当线程读取实例的状态时,实例的状态不会发生变化。实例的状态仅在线程执行写入操作时才会发 生变化。 从实例状态变化来看,读取和写入有本质的区别。 在本模式中,读取操作和写入操作分开考虑。在执行读取操作之前,线程必须获取用于读取的锁。 在执行写入操作之前,线程必须获取用于写入的锁。 可以多个线程同时读取,读取时不可写入。 当线程正在写入时,其他线程不可以读取或写入。 一般来说,执行互斥会降低程序性能。如果把写入的互斥和读取的互斥分开考虑,则可以提高性 能。
示例程序
入口程序
数据对象
读写锁
40 }
41 writingWriters++;
42 }
43
44 public synchronized void writeUnlock() {
45 writingWriters--;
46 preferWriter = false;
47 // 当前线程写入完成,唤醒其他等待的线程进行读写操作
48 notifyAll();
49 }
50
51 }
写线程
读取线程
守护条件
readLock方法和writeLock方法都是用了Guarded Suspension模式。Guarded Suspension模式的重点是守护条件。
readLock方法: 读取线程首先调用readLock方法。当线程从该方法返回,就可以执行实际的读取操作。 当线程开始执行实际的读取操作时,只需要判断是否存在正在写入的线程,以及是否存在正在等待 的写入线程。 不考虑读取线程。 如果存在正在写入的线程或者存在正在等待的写线程,则等待。
writeLock方法: 在线程开始写入之前,调用writeLock方法。当线程从该方法返回后,就可以执行实际的写入操作。 开始执行写入的条件:如果有线程正在执行读取操作,出现读写冲突;或者如果有线程正在执行写 入的操作,引起写冲突,当前线程等待。
Read-Write Lock模式中的角色: Reader 该角色对共享资源角色执行读取操作。 Writer 该角色对共享资源角色执行写操作。 SharedResource 共享资源角色表示Reader角色和Writer角色共享的资源。共享资源角色提供不修改内部状态的操作 (读取)和修改内部状态的操作(写)。 当前案例中对应于Data类。 ReadWriteLock 读写锁角色提供了共享资源角色实现读操作和写操作时需要的锁,即当前案例中的readLock和 readUnlock,以及writeLock和writeUnlock。对应于当前案例中ReadWriteLock类。
要点 1.利用读取操作的线程之间不会冲突的特性来提高程序性能 Read-Write Lock模式利用了读操作的线程之间不会冲突的特性。由于读取操作不会修改共享资源的状态,所以彼此之间无需加锁。因此,多个Reader角色同时执行读取操作,从而提高 程序性能。 2.适合读取操作负载较大的情况 如果单纯使用Single Threaded Execution模式,则read也只能运行一个线程。如果read负载很重,可以使用Read-Write Lock模式。 3.适合少写多读 Read-Write Lock模式优点是Reader之间不会冲突。如果写入很频繁,Writer会频繁停止Reader的处理,也就无法体现出Read-Write Lock模式的优势了。
锁的含义 synchronized可以用于获取实例的锁。java中同一个对象锁不能由两个以上的线程同时获取。 用于读取的锁和用于写入的锁与使用synchronized获取的锁是不一样的。开发人员可以通过修改 ReadWriteLock类来改变锁的运行。 ReadWriteLock类提供了用于读取的锁和用于写入的锁两个逻辑锁,但是实现这两个逻辑锁的物理 锁只有一个,就是ReadWriteLock实例持有的锁。
JUC包和Read-Write Lock模式 java.util.concurrent.locks包提供了已实现Read-Write Lock模式的ReadWriteLock接口和ReentrantReadWriteLock类。 java.util.concurrent.locks.ReadWriteLock接口的功能和当前案例中的ReadWriteLock类类似。不 同之处在于该接口用于读取的锁和用于写入的锁是通过其他对象来实现的。
当前案例的ReadWriteLock java.util.concurrent.locks中的ReadWriteLock接口 readLock() readLock().lock() readUnlock() readLock().unlock() writeLock() writeLock().lock() writeUnlock() writeLock().unlock()
java.util.concurrent.locks.ReentrantReadWriteLock类实现了ReadWriteLock接口。其特征如下: 公平性 当创建ReentrantReadWriteLock类的实例时,可以选择锁的获取顺序是否要设置为fair的。如 果创建的实例是公平的,那么等待时间久的线程将可以优先获取锁。 可重入性 ReentrantReadWriteLock类的锁是可重入的。Reader角色的线程可以获取用于写入的锁, Writer角色的线程可以获取用于读取的锁。 锁降级 ReentrantReadWriteLock类可以按如下顺序将用于写入的锁降级为用于读取的锁:
获取用于写入的锁
获取用于读取的锁
释放用于写入的锁
用于读取的锁不能升级为用于写入的锁。快捷方法 ReentrantReadWriteLock类提供了获取等待中的线程个数的方法 getQueueLength ,以及检查是否获取了用于写入锁的方法isWriteLocked 等方法。
30. Thread-Per-Message模式
该模式可以理解为“每个消息一个线程”。消息这里可以理解为命令或请求。每个命令或请求分配一 个线程,由这个线程来处理。 这就是Thread-Per-Message模式。 在Thread-Per-Message模式中,消息的委托方和执行方是不同的线程。
示例程序 在此示例程序中,ConcurrentDemo类委托Host来显示字符。Host类会创建一个线程,来处理委 托。启动的线程使用Helper类来执行实际的显示。
主入口类
处理器类
工具类
Thread-Per-Message模式中的角色 Client(委托方) Client角色向Host角色发起请求,而不用关心Host角色如何实现该请求处理。当前案例中对应于ConcurrentDemo类。 Host Host角色收到Client角色请求后,创建并启用一个线程。新建的线程使用Helper角色来处理请求。 当前案例中对应于Host类。 Helper Helper角色为Host角色提供请求处理的功能。Host角色创建的新线程调用Helper角色。 当前案例中对应于Helper类。
类图1
要点 1.提高响应性,缩短延迟时间 Thread-Per-Message模式能够提高与Client角色对应的Host角色的响应性,降低延迟时间。 尤其是当handle操作非常耗时或者handle操作需要等待输入/输出时,效果很明显。 为了缩短线程启动花费的时间,可以使用Worker Thread模式。 2.适用于操作顺序没有要求时 在Thread-Per-Message模式中,handle方法并不一定按照request方法的调用顺序来执行。 3.适用于不需要返回值时 在Thread-Per-Message模式中,request方法并不会等待handle方法的执行结束。request得 不到handle的结果。 当需要获取操作结果时,可以使用Future模式。 4.应用于服务器
JUC包和Thread-Per-Message模式
java.lang.Thread类 最基本的创建、启动线程的类 java.lang.Runnable接口 线程锁执行的任务接口java.util.concurrent.ThreadFactory接口将线程创建抽象化的接口java.util.concurrent.Executors 用于创建实例的工具类
java.util.concurrent.Executor接口 将线程执行抽象化的接口java.util.concurrent.ExecutorService接口将被复用的线程抽象化的接口 java.util.concurrent.ScheduledExecutorService类 将被调度线程的执行抽象化的接口
类图2
31. Worker Thread模式
在Worker Thread模式中,工人线程(worker thread)会逐个取回工作并进行处理。当所有工作全部完成后,工人线程会等待新的工作到来。 Worker Thread模式也被称为Background Thread模式。有时也称为Thread Pool模式。 示例程序 ClientThread类的线程会向Channel类发送工作请求(委托)。 Channel类的实例有五个工人线程进行工作。所有工人线程都在等待工作请求的到来。 当收到工作请求后,工人线程会从Channel获取一项工作请求并开始工作。工作完成后,工人线程 回到Channel那里等待下一项工作请求。
类图
时序图
18 19 20 21 22 23 } 24
threadPool = new WorkerThread[threads]; for (int i = 0; i < threadPool.length; i++) { threadPool[i] = new WorkerThread("Worker-" + i, this); }
25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 }
public void startWorkers() { for (int i = 0; i < threadPool.length; i++) { threadPool[i].start(); } }
public synchronized void putRequest(Request request) { while (count >= requestQueue.length) { try { wait(); } catch (InterruptedException e) {
} }
requestQueue[tail] = request; tail = (tail + 1) % requestQueue.length; count++; notifyAll(); }
public synchronized Request takeRequest() { while (count <= 0) { try { wait(); } catch (InterruptedException e) {
} }
Request request = requestQueue[head]; head = (head + 1) % requestQueue.length; count--; notifyAll(); return request; }
Worker Thread模式中的角色 Client(委托者) Client角色创建Request角色并将其传递给Channel角色。在本例中,ClientThread对应Client 角色。 Channel Channel角色接收来自Client角色的Request角色,并将其传递给Worker角色。在本例中, Channel类对应Channel角色。 Worker Worker角色从Channel角色中获取Request角色,并执行其逻辑。当一项工作结束后,继续从Channel获取另外的Request角色。本例中,WorkerThread类对应Worker角色。 Request Request角色表示工作。Request角色中保存了工作的逻辑。本例中,Request类对应Request 角色。
Worker Thread模式的优点 1.提高吞吐量 如果将工作交给其他线程,当前线程就可以处理下一项工作,称为Thread Per Message模式。 由于启动新线程消耗时间,可以通过Worker Thread模式轮流和反复地使用线程来提高吞吐量。 2.容量控制 Worker角色的数量在本例中可以传递参数指定。
Worker角色越多,可以并发处理的逻辑越多。同时增加Worker角色会增加消耗的资源。必须 根据程序实际运行环境调整Worker角色的数量。 3.调用与执行的分离 Worker Thread模式和Thread Per Message模式一样,方法的调用和执行是分开的。方法的调用是invocation,方法的执行是execution。 这样,可以: 提高响应速度; 控制执行顺序,因为执行不受调用顺序的制约; 可以取消和反复执行; 进行分布式部署,通过网络将Request角色发送到其他Woker计算节点进行处理。 4.Runnable接口的意义 java.lang.Runnable 接口有时用作Worker Thread模式的Request角色。即可以创建Runnable接口的实现类对象表示业务逻辑,然后传递给Channel角色。 Runnable对象可以作为方法参数,可以放到队列中,可以跨网络传输,也可以保存到文件 中。如此则Runnable对象不论传输到哪个计算节点,都可以执行。 5.多态的Request角色 本案例中,ClientThread传递给Channel的只是Request实例。但是WorkerThread并不知道 Request类的详细信息。 即使我们传递的是Request的子类给Channel,WorkerThread也可以正常执行execute方法。 通过Request的多态,可以增加任务的种类,而无需修改Channel角色和Worker角色。
JUC包和Worker Thread模式 1.ThreadPoolExecutor类 java.util.concurrent.ThreadPoolExecutor 类是管理Worker线程的类。可以轻松实现 Worker Thread模式。 2.通过java.util.concurrent 包创建线程池 java.util.concurrent.Executors 类就是创建线程池的工具类。
32. Future模式
Future的意思是未来。假设由一个方法需要长时间执行才能获取结果,则一般不会让调用的程序等 待,而是先返回给它一张“提货卡”。获取提货卡并不消耗很多时间。该“提货卡”就是Future角色。 获取Future角色的线程稍后使用Future角色来获取运行结果。
示例程序
类名 说明 Main 向Host发出请求并获取数据 Host 接收请求,并向客户端返回FutureData Data 访问数据方法的接口。 FutureData RealData的“提货单”。 RealData 实际数据的类。构造函数会花费很长时间。
Host类
Data接口:
FutureData类:
RealData类:
22 @Override 23 public String getContent() { 24 return content; 25 } 26 }
Main类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
package com.lagou.concurrent.demo;
public class Main { public static void main(String[] args) { Host host = new Host(); Data data1 = host.request(10, 'A'); Data data2 = host.request(20, 'B'); Data data3 = host.request(30, 'C');
System.out.println("等待一会儿再获取结果");
try {
Thread.sleep(2000);
} catch (InterruptedException e) { e.printStackTrace();
}
18 System.out.println("data1 = " + data1.getContent());
19 System.out.println("data2 = " + data2.getContent());
20 System.out.println("data3 = " + data3.getContent());
21 }
22 }
流程图
Future模式中的角色 Client(请求者) Client角色向Host角色发出请求,并立即接收到请求的处理结果——VirtualData角色,也就是Future角色。 Client角色不必知道返回值是RealData还是Future角色。稍后通过VirtualData角色来操作。 本案例中,对应Main类。 Host Host角色创建新的线程,由新线程创建RealData角色。同时,Host角色将Future角色(当做VirtualData角色)返回给Client角色。本案例中对应Host类。 VirtualData(虚拟数据) VirtualData角色是让Future角色与RealData角色具有一致性的角色。本案例中对应Data接 口。 RealData(真实数据) RealData角色是表示真实数据的角色。创建该对象需要花费很多时间。本案例中对应RealData类。 Future Future角色是RealData角色的“提货单”,由Host角色传递给Client角色。对Client而言, Future角色就是VirtualData角色。当Client角色操作Future角色时线程会wait,直到RealData 角色创建完成。
Future角色将Client角色的操作委托给RealData角色。本案例中,对应于FutureData类。
要点: 1.使用Thread Per Message模式,可以提高程序响应性,但是不能获取结果。Future模式也可以提高程序响应性,还可以获取处理结果。 2.利用Future模式异步处理特性,可以提高程序吞吐量。虽然并没有减少业务处理的时长,但是 如果考虑到I/O,当程序进行磁盘操作时,CPU只是处于等待状态。CPU有空闲时间处理其他 的任务。 3.“准备返回值”和“使用返回值”的分离。 4.如果想等待处理完成后获取返回值,还可以考虑采用回调处理方式。即,当处理完成后,由Host角色启动的线程调用Client角色的方法,进行结果的处理。此时Client角色中的方法需要 线程安全地传递返回值。
JUC包与Future模式
java.util.concurrent包提供了用于支持Future模式的类和接口。
java.util.concurrent.Callable接口将“返回值的某种处理调用”抽象化了。Callable接口声明了call方 法。call方法类似于Runnable的run方法,但是call方法有返回值。Callable
Callable、Future、FutureTask的类图